
Cramers V ist ein Maß für die Stärke des Zusammenhangs zwischen zwei nominalen Variablen.
Es reicht von 0 bis 1, wobei:
- 0 zeigt keine Assoziation zwischen den beiden Variablen an …
Ein Chi-Quadrat-Anpassungstest wird verwendet, um zu bestimmen, ob eine kategoriale Variable einer hypothetischen Verteilung folgt oder nicht.
In diesem Tutorial wird erklärt, wie ein Chi-Quadrat-Anpassungstest in Stata durchgeführt wird.
Um zu veranschaulichen, wie dieser Test durchgeführt wird, verwenden wir einen Datensatz namens nlsw88, der Informationen zur Arbeitsstatistik für Frauen in den USA von 1988 enthält.
Führen Sie die folgenden Schritte aus, um einen Chi-Quadrat-Anpassungstest durchzuführen, um festzustellen, ob die tatsächliche Verteilung der Rasse in diesem Datensatz wie folgt ist: 70% Weiß, 20% Schwarz, 10% Andere.
Schritt 1: Laden Sie die Rohdaten und zeigen Sie sie an.
Zuerst laden wir die Daten, indem wir den folgenden Befehl eingeben:
sysuse nlsw88
Wir können die Rohdaten anzeigen, indem wir den folgenden Befehl eingeben:
br
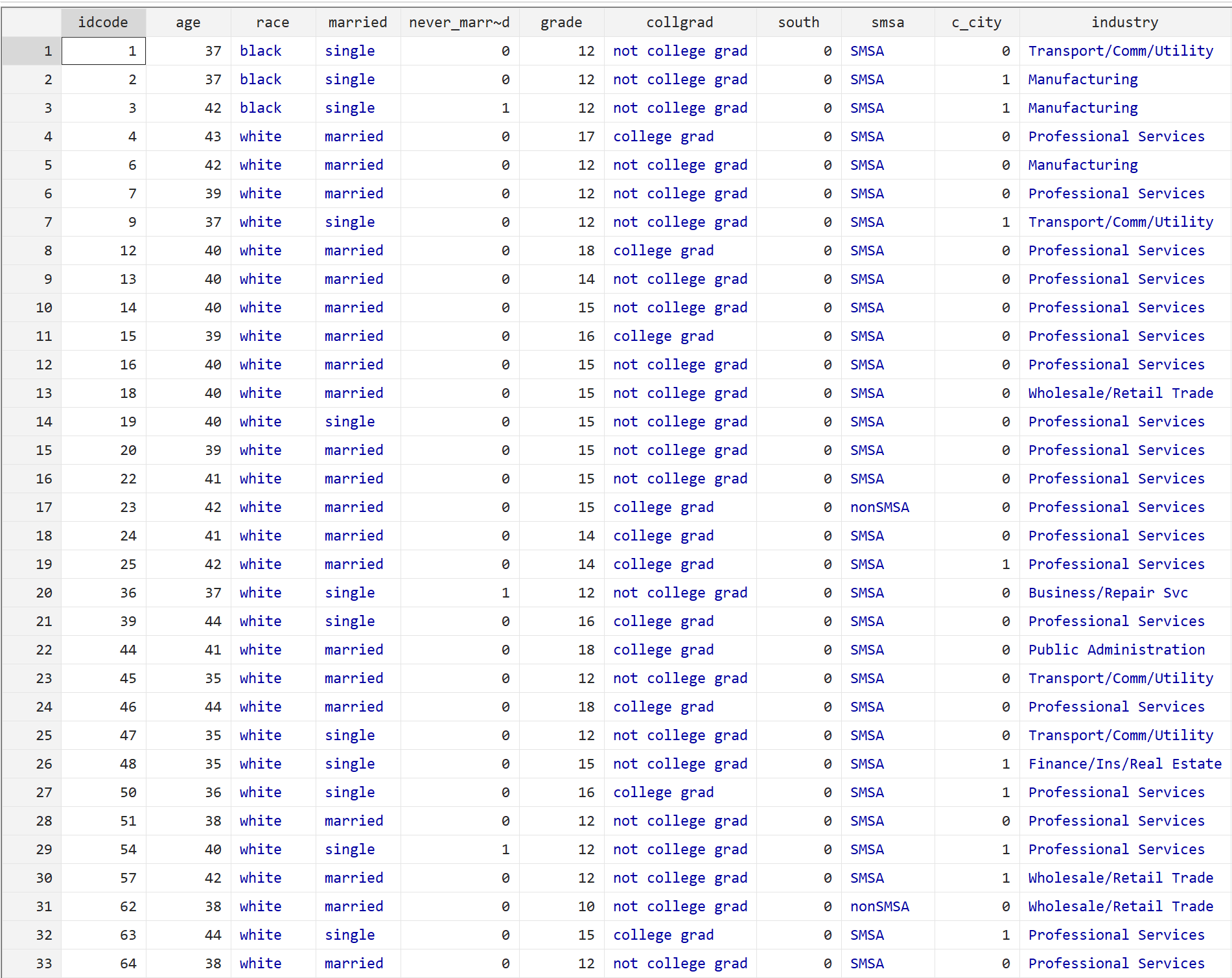
In jeder Zeile werden Informationen für eine Person angezeigt, einschließlich Alter, Rasse, Familienstand, Bildungsniveau und einer Vielzahl anderer Faktoren.
Schritt 2: Laden Sie das Fit-Paket.
Um einen Chi-Quadrat-Anpassungstest durchzuführen, müssen wir das csgof-Paket installieren. Wir können dies tun, indem wir den folgenden Befehl eingeben:
findit csgof
Ein neues Fenster wird geöffnet. Klicken Sie auf den Link csgof from https://stats.idre.ucla.edu/stat/stata/ado/analysis.
Ein weiteres Fenster wird geöffnet. Klicken Sie auf den Link, der besagt: click here to install.
Die Installation des Pakets sollte nur einige Sekunden dauern.
Schritt 3: Führen Sie den Anpassungstest durch.
Sobald das Paket installiert ist, können wir den Chi-Quadrat-Anpassungstest für die Daten durchführen, um festzustellen, ob die tatsächliche Verteilung des Rennens wie folgt ist: 70% Weiß, 20% Schwarz, 10% Andere.
Wir werden die folgende Syntax verwenden, um den Test durchzuführen:
csgof variable_of_interest, expperc(list_of_expected_percentages)
Hier ist die genaue Syntax, die wir in unserem Fall verwenden werden:
csgof race, expperc(70, 20, 10)

So interpretieren Sie die Ausgabe:
Zusammenfassungsbox: Dieses Feld zeigt uns den erwarteten Prozentsatz, die erwartete Häufigkeit und die beobachtete Häufigkeit für jedes Rennen. Beispielsweise:
Chisq(2): Dies ist die Chi-Quadrat-Teststatistik für den Anpassungstest. Es stellt sich heraus, 218,13 zu sein.
p: Dies ist der p-Wert, der der Chi-Quadrat-Teststatistik zugeordnet ist. Es stellt sich heraus, dass es 0 ist. Da dies weniger als 0,05 ist, können wir die Nullhypothese, dass die wahre Verteilung der Rasse 70% Weiß, 20% Schwarz, 10% Andere ist, nicht ablehnen. Wir haben genügend Beweise, um zu dem Schluss zu kommen, dass sich die wahre Verteilung der Rasse von dieser hypothetischen Verteilung unterscheidet.
Cramers V ist ein Maß für die Stärke des Zusammenhangs zwischen zwei nominalen Variablen.
Es reicht von 0 bis 1, wobei:
Ein Phi-Koeffizient ist ein Maß für die Assoziation zwischen zwei binären Variablen.
Um den Phi-Koeffizienten für eine 2 × 2-Tabelle mit zwei Zufallsvariablen zu berechnen, füllen Sie einfach die Zellen der …