
Eine einfaktorielle ANOVA wird verwendet, um zu bestimmen, ob es einen statistisch signifikanten Unterschied zwischen den Mittelwerten von drei oder mehr unabhängigen Gruppen gibt oder nicht.
Das folgende Beispiel bietet …
Eine ANOVA mit wiederholten Messungen wird verwendet, um zu bestimmen, ob es einen statistisch signifikanten Unterschied zwischen den Mittelwerten von drei oder mehr Gruppen gibt, in denen in jeder Gruppe dieselben Probanden auftauchen.
In diesem Tutorial wird erklärt, wie Sie eine einfaktorielle ANOVA mit wiederholten Messungen von Hand durchführen.
Forscher wollen wissen, ob drei verschiedene Medikamente zu unterschiedlichen Reaktionszeiten führen. Um dies zu testen, messen sie die Reaktionszeit (in Sekunden) von fünf Patienten mit jedem Medikament. Die Ergebnisse sind unten gezeigt:
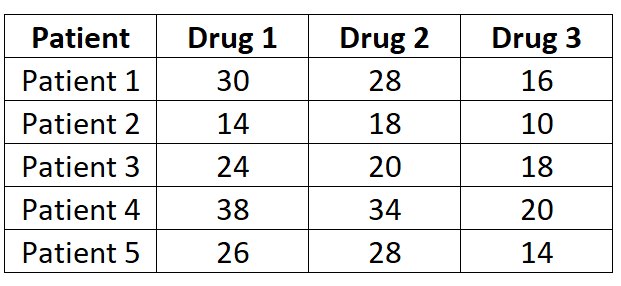
Da jeder Patient an jedem der drei Medikamente gemessen wird, verwenden wir eine ANOVA mit wiederholten Einwegmessungen, um festzustellen, ob die mittlere Reaktionszeit zwischen den Medikamenten unterschiedlich ist.
Führen Sie die folgenden Schritte aus, um die ANOVA mit wiederholten Messungen von Hand durchzuführen:
Schritt 1: Berechnen Sie den SST.
Zunächst berechnen wir die Gesamtsumme der Quadrate (SST), die mit der folgenden Formel ermittelt werden kann:
SST = s 2gesamt (n gesamt -1)
wo:
In diesem Beispiel berechnen wir SST zu: (64.2667) (15-1) = 899.7
Schritt 2: Berechnen Sie den SSB
Als nächstes berechnen wir die Summe der Quadrate (SSB), die mit der folgenden Formel ermittelt werden kann:
SSB = Σn j ( x j – x gesamt ) 2
wo:
In diesem Beispiel berechnen wir SSB als: (5) (26,4-22,533) 2 + (5) (25,6-22,533) 2 + (5) (15,6-22,533) 2 = 362,1
Schritt 3: SSS berechnen.
Als nächstes berechnen wir die Subjektsumme der Quadrate (SSS), die mit der folgenden Formel ermittelt werden kann:
SSS = (Σr 2k / c) – (N 2 / rc)
wo:
In diesem Beispiel berechnen wir SSS wie folgt: ((74 2 + 42 2 + 62 2 + 92 2 + 68 2 ) / 3) – (338 2 / (6) (3)) = 441,1
Schritt 4: Berechnen Sie die SSE.
Als nächstes berechnen wir die Fehlersumme der Quadrate (SSE), die mit der folgenden Formel ermittelt werden kann:
SSE = SST – SSB – SSS
In diesem Beispiel berechnen wir SSE zu: 899,7 – 362,1 – 441,1 = 96,5
Schritt 5: Füllen Sie die ANOVA-Tabelle für wiederholte Messungen aus.
Nachdem wir nun SSB, SSS und SSE haben, können wir die ANOVA-Tabelle für wiederholte Messungen ausfüllen:
| Quelle | Summe der Quadrate (SS) | df | Mittlere Quadrate (MS) | F. |
|---|---|---|---|---|
| Between | 362.1 | 2 | 181.1 | 15.006 |
| Subject | 441.1 | 4 | 110.3 | |
| Error | 96,5 | 8 | 12.1 |
So haben wir die verschiedenen Zahlen in der Tabelle berechnet:
Schritt 6: Interpretieren Sie die Ergebnisse.
Die F-Teststatistik für diese einfaktorielle ANOVA mit wiederholten Messungen beträgt 15.006. Um festzustellen, ob dies ein statistisch signifikantes Ergebnis ist, müssen wir dies mit dem F-kritischen Wert in der F-Verteilungstabelle mit den folgenden Werten vergleichen:
Wir finden, dass der kritische F-Wert 4,459 beträgt.
Da die F-Teststatistik in der ANOVA-Tabelle größer als der F-kritische Wert in der F-Verteilungstabelle ist, lehnen wir die Nullhypothese ab. Dies bedeutet, dass wir genügend Beweise haben, um zu sagen, dass es einen statistisch signifikanten Unterschied zwischen den mittleren Reaktionszeiten der Medikamente gibt.
Eine einfaktorielle ANOVA wird verwendet, um zu bestimmen, ob es einen statistisch signifikanten Unterschied zwischen den Mittelwerten von drei oder mehr unabhängigen Gruppen gibt oder nicht.
Das folgende Beispiel bietet …
Eine geschachtelte ANOVA ist eine Art ANOVA („Varianzanalyse“), bei der mindestens ein Faktor in einem anderen Faktor verschachtelt ist.
Nehmen wir zum Beispiel an, ein Forscher möchte wissen, ob drei …