
Eine einfaktorielle ANOVA wird verwendet, um zu bestimmen, ob es einen statistisch signifikanten Unterschied zwischen den Mittelwerten von drei oder mehr unabhängigen Gruppen gibt oder nicht.
Das folgende Beispiel bietet …
Dieses Tutorial enthält ein Beispiel für die Durchführung einer ANCOVA in R
Wir werden eine ANCOVA durchführen, um anhand der folgenden Variablen zu testen, ob sich das Studium auf die Prüfungsergebnisse auswirkt oder nicht:
Der folgende Datensatz enthält Informationen für 90 Schüler, die zufällig in drei Gruppen zu je 30 Personen aufgeteilt wurden. Der Datensatz zeigt die von jedem Schüler verwendete Lerntechnik (A, B oder C) , ihre aktuelle Note in der Klasse, als sie mit der Lerntechnik begannen. und ihre Prüfungsergebnisse, die sie erhalten haben, nachdem sie einen Monat lang die Lerntechnik angewendet hatten, um sich auf die Prüfung vorzubereiten:
#Machen Sie dieses Beispiel reproduzierbar
set.seed (10)
#Datensatz erstellen
data <- data.frame(technique = rep(c("A", "B", "C"), each = 30),
current_grade = runif(90, 65, 95),
exam = c(runif(30, 80, 95), runif(30, 70, 95), runif(30, 70, 90)))
# Die ersten sechs Zeilen des Datensatzes anzeigen
head(data)
# technique current_grade exam
#1 A 80.22435 87.32759
#2 A 74.20306 90.67114
#3 A 77.80723 88.87902
#4 A 85.79306 87.75735
#5 A 67.55408 85.72442
#6 A 71.76310 92.52167
Bevor wir das ANCOVA-Modell anpassen, sollten wir zunächst die Daten untersuchen, um sie besser zu verstehen und sicherzustellen, dass es keine extremen Ausreißer gibt, die die Ergebnisse verzerren könnten.
Zunächst können wir eine Zusammenfassung jeder Variablen im Datensatz anzeigen:
summary(data)
# technique current_grade exam
# A:30 Min. :65.43 Min. :71.17
# B:30 1st Qu.:71.79 1st Qu.:77.27
# C:30 Median :77.84 Median :84.69
# Mean :78.15 Mean :83.38
# 3rd Qu.:83.65 3rd Qu.:89.22
# Max. :93.84 Max. :94.76
Wir können sehen, dass jeder Wert für das Studium der Technik ( A, B und C) 30 Mal in den Daten erscheint.
Wir können auch sehen, wie die aktuellen Schülerergebnisse zu Beginn der Studie verteilt wurden. Die Mindestpunktzahl in der Klasse betrug 65,43, die Höchstpunktzahl 93,84 und der Mittelwert 78,15.
Ebenso können wir sehen, dass die Mindestpunktzahl für die Prüfung 71,17 betrug, die Höchstpunktzahl 94,76 betrug und der Mittelwert 83,38 betrug.
Als nächstes können wir das dplyr-Paket verwenden, um den Mittelwert und die Standardabweichung sowohl der aktuellen Noten als auch der Prüfungsergebnisse für jede Lerntechnik leicht zu ermitteln:
#dplyr laden
library(dplyr)
data %>%
group_by(technique) %>%
summarise(mean_grade = mean(current_grade),
sd_grade = sd(current_grade),
mean_exam = mean(exam),
sd_exam = sd(exam))
# A tibble: 3 x 5
# technique mean_grade sd_grade mean_exam sd_exam
#1 A 79.0 7.00 88.5 3.88
#2 B 78.5 8.33 81.8 7.62
#3 C 76.9 8.24 79.9 5.71
Wir können sehen, dass der Mittelwert und die Standardabweichungen der aktuellen Note für die Schüler, die jede Lerntechnik anwenden, ungefähr ähnlich sind.
Wir können auch sehen, dass die durchschnittliche Prüfungspunktzahl für die Schüler, die Technik A studiert haben, im Vergleich zu Technik B und C deutlich höher ist.
Wir können auch die Verteilung der Prüfungsergebnisse basierend auf der Lerntechnik mithilfe von Boxplots visualisieren:
boxplot(exam ~ technique,
data = data,
main = "Exam Score by Studying Technique",
xlab = "Studying Technique",
ylab = "Exam Score",
col = "steelblue",
border = "black"
)

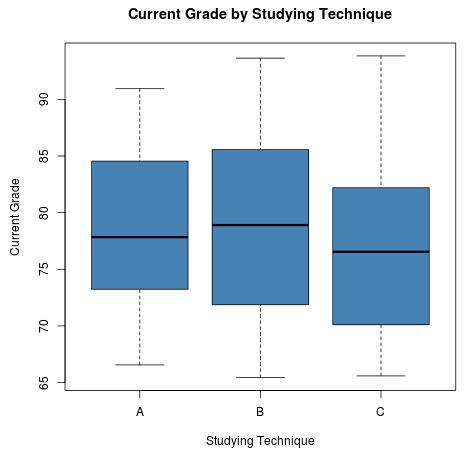
In ähnlicher Weise können wir auch Boxplots verwenden, um die Verteilung der aktuellen Noten basierend auf der Lerntechnik zu visualisieren:
boxplot(current_grade ~ technique,
data = data,
main = "Current Grade by Studying Technique",
xlab = "Studying Technique",
ylab = "Current Grade",
col = "steelblue",
border = "black"
)
Nachdem wir einige grundlegende Datenexplorationen durchgeführt haben und mit den Daten vertraut sind, müssen wir überprüfen, ob die folgenden Annahmen für ANCOVA erfüllt sind:
Um zu überprüfen, ob die Kovariate und die Behandlung unabhängig sind, können wir eine ANOVA unter Verwendung des aktuellen Grades als Antwortvariable und der Untersuchungstechnik als Prädiktorvariable durchführen:
#Anova Modell anpassen
anova_model <- aov(current_grade ~ technique, data = data)
#Zusammenfassung des Anova-Modells anzeigen
summary(anova_model)
# Df Sum Sq Mean Sq F value Pr(>F)
#technique 2 74 37.21 0.599 0.552
#Residuals 87 5406 62.14
Der p-Wert ist größer als 0,05, daher scheinen die Kovariate (aktuelle Note) und die Behandlung (Lerntechnik) unabhängig zu sein.
Um zu überprüfen, ob zwischen den Gruppen eine Homogenität der Varianz besteht, können wir den Levene-Test durchführen:
#car Bibliothek laden, um Levene-Test durchzuführen
libary(car)
#Levene Test durchführen
leveneTest(exam~technique, data = data)
#Levene's Test for Homogeneity of Variance (center = median)
# Df F value Pr(>F)
#group 2 9.4324 0.0001961 ***
# 87
Der p-Wert aus dem Test ist gleich .0001961, was darauf hinweist, dass die Varianzen zwischen den Gruppen nicht gleich sind. Obwohl wir versuchen könnten, die Daten zu transformieren, um dieses Problem zu beheben, werden wir uns vorerst nicht allzu viele Sorgen um die Unterschiede in der Varianz machen.
Als nächstes passen wir das ANCOVA-Modell an, indem wir den Prüfungswert als Antwortvariable verwenden, die Technik als Prädiktor- (oder „Behandlungs-“) Variable und die aktuelle Note als Kovariate.
Wir werden dazu die Anova() – Funktion im Fahrzeugpaket verwenden, damit wir angeben können, dass wir die Quadratsumme vom Typ III für das Modell verwenden möchten, da die Quadratsumme vom Typ I von der Reihenfolge abhängt, in der sie sich befindet Die Prädiktoren werden in das Modell eingegeben:
#car Bibliothek laden
library(car)
#ANCOVA Modell anpassen
ancova_model <- aov(exam ~ technique + current_grade, data = data)
#Zusammenfassung des Modells anzeigen
Anova(ancova_model, type="III")
#Response: exam
# Sum Sq Df F value Pr(>F)
#(Intercept) 7161.2 1 201.4621 < 2.2e-16 ***
#technique 1242.9 2 17.4830 4.255e-07 ***
#current_grade 12.3 1 0.3467 0.5576
#Residuals 3057.0 86
Wir können sehen, dass der p-Wert für die Technik extrem klein ist, was darauf hinweist, dass das Studieren der Technik einen statistisch signifikanten Einfluss auf die Prüfungsergebnisse hat, selbst nach Kontrolle der aktuellen Note.
Obwohl die ANCOVA Ergebnisse uns gesagt, dass „Studiertechnik“ auf die Prüfungsergebnisse einen statistisch signifikanten Effekt hatte, müssen wir den Post–hoc–Tests durchführen, um tatsächlich herauszufinden, wie sich die Studiertechniken voneinander unterscheiden.
Zu diesem Zweck können wir die Funktion glht() im multcomp-Paket in R verwenden, um den Tukey-Test für mehrere Vergleiche durchzuführen:
#Laden Sie die Multcomp- Bibliothek
library(multcomp)
#Anpassen des ANCOVA-Modells
ancova_model <- aov(exam ~ technique + current_grade, data = data)
#Definieren Sie die durchzuführenden Post-Hoc-Vergleiche
postHocs <- glht(ancova_model, linfct = mcp(technique = "Tukey"))
# eine Zusammenfassung der Post-hoc-Vergleiche anzeigen
summary(postHocs)
#Multiple Comparisons of Means: Tukey Contrasts
#
#Fit: aov(formula = exam ~ technique + current_grade, data = data)
#
#Linear Hypotheses:
# Estimate Std. Error t value Pr(>|t|)
#B - A == 0 -6.711 1.540 -4.358 0.000109 ***
#C - A == 0 -8.736 1.549 -5.640 < 1e-04 ***
#C - B == 0 -2.025 1.545 -1.311 0.393089
# Sehen Sie sich die Konfidenzintervalle an, die mit den Mehrfachvergleichen verbunden sind
confint(postHocs)
# Simultaneous Confidence Intervals
#
#Multiple Comparisons of Means: Tukey Contrasts
#
#Fit: aov(formula = exam ~ technique + current_grade, data = data)
#
#Quantile = 2.3845
#95% family-wise confidence level
#
#Linear Hypotheses:
# Estimate lwr upr
#B - A == 0 -6.7112 -10.3832 -3.0392
#C - A == 0 -8.7364 -12.4302 -5.0426
#C - B == 0 -2.0252 -5.7091 1.6588
Aus der Ausgabe können wir erkennen, dass es einen statistisch signifikanten Unterschied (bei α = 0,05) in den Prüfungsergebnissen zwischen dem Studium von Technik A und dem Studium von Technik B (p-Wert: .000109) sowie zwischen Technik A und Technik C gibt ( p-Wert: <1e-04).
Wir können auch sehen, dass es keinen statistisch signifikanten Unterschied (bei α = 0,05) zwischen den Techniken B und C gibt. Die Konfidenzintervalle zwischen den Techniken bestätigen diese Schlussfolgerungen ebenfalls.
Wir können daher den Schluss ziehen, dass die Verwendung von Lerntechnik A zu einer statistisch signifikant höheren Prüfungsbewertung für Schüler im Vergleich zu Technik B und C führt, selbst nachdem die aktuelle Note des Schülers in der Klasse kontrolliert wurde.
Eine einfaktorielle ANOVA wird verwendet, um zu bestimmen, ob es einen statistisch signifikanten Unterschied zwischen den Mittelwerten von drei oder mehr unabhängigen Gruppen gibt oder nicht.
Das folgende Beispiel bietet …
Eine geschachtelte ANOVA ist eine Art ANOVA („Varianzanalyse“), bei der mindestens ein Faktor in einem anderen Faktor verschachtelt ist.
Nehmen wir zum Beispiel an, ein Forscher möchte wissen, ob drei …