
Das Latin Hypercube Stichprobenverfahren ist eine Methode, die zur Stichprobenziehung von Zufallszahlen verwendet werden kann, bei der die Stichproben gleichmäßig über einen Stichprobenraum verteilt sind.
Es wird häufig verwendet, um …
Zufallszuteilung und Zufallszuweisung (auch zufällige Auswahl und zufällige Zuordnung) sind zwei Techniken in der Statistik, die häufig verwendet werden, aber häufig verwechselt werden.
Zufallszuteilung bezieht sich auf den Prozess der zufälligen Auswahl von Personen aus einer Population, die an einer Studie beteiligt sein sollen.
Die Zufallszuweisung bezieht sich auf den Prozess der zufälligen Zuordnung der Personen in einer Studie entweder zu einer Behandlungsgruppe oder zu einer Kontrollgruppe.
Sie können sich die Zufallszuteilung als den Prozess vorstellen, mit dem Sie die Personen in einer Studie „erhalten“, und Sie können sich die zufällige Zuordnung als das vorstellen, was Sie mit diesen Personen „tun“, sobald sie als Teil der Studie ausgewählt wurden.
Wenn eine Studie eine zufällige Auswahl verwendet, wählt sie Personen aus einer Population nach einem zufälligen Verfahren aus. Wenn beispielsweise eine Bevölkerung 1.000 Personen hat, können wir einen Computer verwenden, um 100 dieser Personen zufällig aus einer Datenbank auszuwählen. Dies bedeutet, dass jedes Individuum mit gleicher Wahrscheinlichkeit als Teil der Studie ausgewählt wird, was die Wahrscheinlichkeit erhöht, dass wir eine repräsentative Stichprobe erhalten – eine Stichprobe, die ähnliche Merkmale wie die Gesamtbevölkerung aufweist.
Durch die Verwendung einer repräsentativen Stichprobe in unserer Studie können wir die Ergebnisse unserer Studie auf die Bevölkerung übertragen. In statistischer Hinsicht wird dies als externe Validität bezeichnet – es gilt, unsere Ergebnisse auf die Gesamtbevölkerung zu übertragen.
Wenn eine Studie eine zufällige Zuordnung verwendet, werden Personen zufällig entweder einer Behandlungsgruppe oder einer Kontrollgruppe zugeordnet. Wenn wir beispielsweise 100 Personen in einer Studie haben, können wir einen Zufallszahlengenerator verwenden, um zufällig 50 Personen einer Kontrollgruppe und 50 Personen einer Behandlungsgruppe zuzuweisen.
Durch die Verwendung einer zufälligen Zuordnung erhöhen wir die Wahrscheinlichkeit, dass die beiden Gruppen ungefähr ähnliche Eigenschaften aufweisen, was bedeutet, dass jeder Unterschied, den wir zwischen den beiden Gruppen beobachten, auf die Behandlung zurückgeführt werden kann. Dies bedeutet, dass die Studie eine interne Validität hat – es ist gültig, Unterschiede zwischen den Gruppen der Behandlung selbst zuzuschreiben, im Gegensatz zu Unterschieden zwischen den Individuen in den Gruppen.
Es ist möglich, dass eine Studie sowohl zufällige Auswahl als auch zufällige Zuordnung verwendet oder nur eine dieser Techniken oder keine der beiden Techniken. Eine starke Studie verwendet beide Techniken.
Die folgenden Beispiele zeigen, wie eine Studie beide, eine oder keine dieser Techniken zusammen mit den Auswirkungen verwenden kann.
Studie: Forscher möchten wissen, ob eine neue Diät in einer bestimmten Gemeinschaft von 10.000 Menschen zu mehr Gewichtsverlust führt als eine Standarddiät. Sie rekrutieren 100 Personen für die Studie, indem sie mithilfe eines Computers zufällig 100 Namen aus einer Datenbank auswählen. Sobald sie die 100 Individuen haben, verwenden sie erneut einen Computer, um 50 der Individuen zufällig einer Kontrollgruppe zuzuordnen (z. B. bei ihrer Standarddiät zu bleiben) und 50 Individuen einer Behandlungsgruppe zuzuordnen (z. B. der neuen Diät zu folgen). Sie erfassen den Gesamtgewichtsverlust jedes Einzelnen nach einem Monat.

Ergebnisse: Die Forscher verwendeten eine zufällige Auswahl, um ihre Stichprobe und zufällige Zuordnung zu erhalten, wenn Personen entweder einer Behandlungs- oder einer Kontrollgruppe zugeordnet wurden. Auf diese Weise können sie die Ergebnisse der Studie auf die Gesamtbevölkerung übertragen und Unterschiede im durchschnittlichen Gewichtsverlust zwischen den beiden Gruppen auf die neue Ernährung zurückführen.
Studie: Forscher möchten wissen, ob eine neue Diät in einer bestimmten Gemeinschaft von 10.000 Menschen zu mehr Gewichtsverlust führt als eine Standarddiät. Sie rekrutieren 100 Personen für die Studie, indem sie mithilfe eines Computers zufällig 100 Namen aus einer Datenbank auswählen. Sie beschließen jedoch, Einzelpersonen Gruppen zuzuordnen, die ausschließlich auf dem Geschlecht beruhen. Frauen werden der Kontrollgruppe und Männer der Behandlungsgruppe zugeordnet. Sie erfassen den Gesamtgewichtsverlust jedes Einzelnen nach einem Monat.
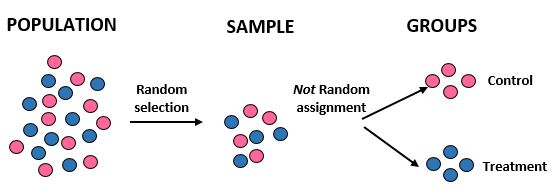
Ergebnisse: Die Forscher verwendeten eine zufällige Auswahl, um ihre Stichprobe zu erhalten, verwendeten jedoch keine zufällige Zuordnung, wenn Personen entweder einer Behandlungs- oder einer Kontrollgruppe zugeordnet wurden. Stattdessen verwendeten sie einen bestimmten Faktor – das Geschlecht -, um zu entscheiden, welcher Gruppe Personen zugeordnet werden sollen. Auf diese Weise können sie die Ergebnisse der Studie auf die Gesamtbevölkerung übertragen, aber sie können der neuen Ernährung keine Unterschiede beim durchschnittlichen Gewichtsverlust zwischen den beiden Gruppen zuschreiben. Die interne Validität der Studie wurde beeinträchtigt, da der Unterschied beim Gewichtsverlust eher auf das Geschlecht als auf die neue Ernährung zurückzuführen sein könnte.
Studie: Forscher möchten wissen, ob eine neue Diät in einer bestimmten Gemeinschaft von 10.000 Menschen zu mehr Gewichtsverlust führt als eine Standarddiät. Sie rekrutieren 100 männliche Athleten, um an der Studie teilzunehmen. Anschließend verwenden sie ein Computerprogramm, um 50 männliche Athleten zufällig einer Kontrollgruppe und 50 der Behandlungsgruppe zuzuordnen. Sie erfassen den Gesamtgewichtsverlust jedes Einzelnen nach einem Monat.
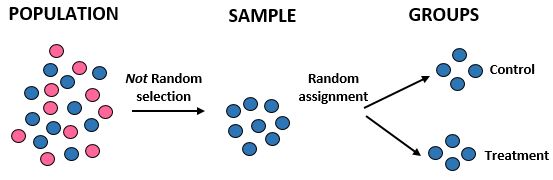
Ergebnisse: Die Forscher verwendeten keine zufällige Auswahl, um ihre Stichprobe zu erhalten, da sie speziell 100 männliche Athleten auswählten. Aus diesem Grund ist ihre Stichprobe nicht repräsentativ für die Gesamtbevölkerung, sodass ihre externe Validität beeinträchtigt wird. Sie können die Ergebnisse der Studie nicht auf die Gesamtbevölkerung übertragen. Sie verwendeten jedoch eine zufällige Zuordnung, was bedeutet, dass sie der neuen Diät jeden Unterschied beim Gewichtsverlust zuschreiben können.
Studie: Forscher möchten wissen, ob eine neue Diät in einer bestimmten Gemeinschaft von 10.000 Menschen zu mehr Gewichtsverlust führt als eine Standarddiät. Sie rekrutieren 50 männliche Athleten und 50 weibliche Athleten, um an der Studie teilzunehmen. Dann ordnen sie alle weiblichen Athleten der Kontrollgruppe und alle männlichen Athleten der Behandlungsgruppe zu. Sie erfassen den Gesamtgewichtsverlust jedes Einzelnen nach einem Monat.
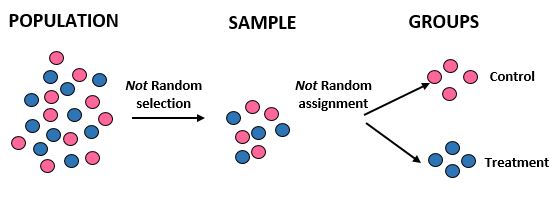
Ergebnisse: Die Forscher verwendeten keine zufällige Auswahl, um ihre Stichprobe zu erhalten, da sie speziell 100 Athleten auswählten. Aus diesem Grund ist ihre Stichprobe nicht repräsentativ für die Gesamtbevölkerung, sodass ihre externe Validität beeinträchtigt wird. Sie können die Ergebnisse der Studie nicht auf die Gesamtbevölkerung übertragen. Außerdem teilen sie Einzelpersonen eher nach Geschlecht als nach zufälliger Zuordnung in Gruppen ein, was bedeutet, dass auch ihre interne Gültigkeit beeinträchtigt wird – Unterschiede beim Gewichtsverlust können eher auf das Geschlecht als auf die Ernährung zurückzuführen sein.
Das Latin Hypercube Stichprobenverfahren ist eine Methode, die zur Stichprobenziehung von Zufallszahlen verwendet werden kann, bei der die Stichproben gleichmäßig über einen Stichprobenraum verteilt sind.
Es wird häufig verwendet, um …
Zwei der wichtigsten Arten von Variablen, die in der Statistik zu verstehen sind, sind erklärende Variablen und Antwortvariablen.
Erklärende Variable: Diese Variable wird manchmal als unabhängige Variable oder Prädiktorvariable bezeichnet …