
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
- K: Die Anzahl der Modellparameter …
Ein lineares Regressionsmodell kann für zwei Dinge nützlich sein:
(1) Quantifizieren der Beziehung zwischen einer oder mehreren Prädiktorvariablen und einer Antwortvariablen.
(2) Verwenden des Modells zur Vorhersage zukünftiger Werte.
In Bezug auf (2) sind wir häufig daran interessiert, sowohl einen genauen Wert als auch ein Intervall vorherzusagen, das einen Bereich wahrscheinlicher Werte enthält, wenn wir ein Regressionsmodell verwenden, um zukünftige Werte vorherzusagen. Dieses Intervall wird als Vorhersageintervall bezeichnet.
Angenommen, wir passen ein einfaches lineares Regressionsmodell an, bei dem die Stunden als Prädiktorvariable und der Prüfungswert als Antwortvariable untersucht werden. Mit diesem Modell können wir vorhersagen, dass ein Student, der 6 Stunden studiert, eine Prüfungsnote von 91 erhält.
Da diese Vorhersage jedoch ungewiss ist, können wir ein Vorhersageintervall erstellen, das besagt, dass eine Wahrscheinlichkeit von 95% besteht, dass ein Student, der 6 Stunden lang studiert, eine Prüfungsnote zwischen 85 und 97 erhält. Dieser Wertebereich wird als 95%-Vorhersageintervall bezeichnet und ist für uns oft nützlicher, als nur den genauen vorhergesagten Wert zu kennen.
Um zu veranschaulichen, wie ein Vorhersageintervall in R erstellt wird, verwenden wir den integrierten MTCAR- Datensatz, der Informationen zu den Merkmalen mehrerer verschiedener Fahrzeuge enthält:
#Erste sechs Reihen von mtcars anzeigen
head(mtcars)
# mpg cyl disp hp drat wt qsec vs am gear carb
#Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
#Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
#Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
#Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
#Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
#Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
Zunächst passen wir ein einfaches lineares Regressionsmodell an, wobei disp als Prädiktorvariable und mpg als Antwortvariable verwendet werden.
#Einfaches lineares Regressionsmodell anpassen
model <- lm(mpg ~ disp, data = mtcars)
# Zusammenfassung des angepassten Modells anzeigen
summary(model)
#Call:
#lm(formula = mpg ~ disp, data = mtcars)
#
#Residuals:
# Min 1Q Median 3Q Max
#-4.8922 -2.2022 -0.9631 1.6272 7.2305
#
#Coefficients:
# Estimate Std. Error t value Pr(>|t|)
#(Intercept) 29.599855 1.229720 24.070 < 2e-16 ***
#disp -0.041215 0.004712 -8.747 9.38e-10 ***
#---
#Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#
#Residual standard error: 3.251 on 30 degrees of freedom
#Multiple R-squared: 0.7183, Adjusted R-squared: 0.709
#F-statistic: 76.51 on 1 and 30 DF, p-value: 9.38e-10
Dann verwenden wir das angepasste Regressionsmodell, um den Wert von mpg basierend auf drei neuen Werten für disp vorherzusagen.
#Datafrane mit drei neuen Werten für disp erstellen
new_disp <- data.frame(disp= c(150, 200, 250))
#Verwenden Sie das angepasste Modell, um den Wert für mpg basierend auf den drei neuen Werten für disp vorherzusagen
predict(model, newdata = new_disp)
# 1 2 3
#23.41759 21.35683 19.29607
Diese Werte können folgendermaßen interpretiert werden:
Als nächstes verwenden wir das angepasste Regressionsmodell, um Vorhersageintervalle um diese vorhergesagten Werte herum zu erstellen:
#Erstellen Sie Vorhersageintervalle um die vorhergesagten Werte
predict(model, newdata = new_disp, interval = "predict")
# fit lwr upr
#1 23.41759 16.62968 30.20549
#2 21.35683 14.60704 28.10662
#3 19.29607 12.55021 26.04194
Diese Werte können folgendermaßen interpretiert werden:
Standardmäßig verwendet R ein Vorhersageintervall von 95%. Mit dem Befehl level können wir dies jedoch nach Belieben ändern. Der folgende Code veranschaulicht beispielsweise, wie 99%-Vorhersageintervalle erstellt werden:
#99% Vorhersageintervalle um die vorhergesagten Werte erstellen
predict(model, newdata = new_disp, interval = "predict", level = 0.99)
# fit lwr upr
#1 23.41759 14.27742 32.55775
#2 21.35683 12.26799 30.44567
#3 19.29607 10.21252 28.37963
Beachten Sie, dass die Vorhersageintervalle von 99% breiter sind als die Vorhersageintervalle von 95%. Dies ist sinnvoll, da je größer das Intervall ist, desto höher ist die Wahrscheinlichkeit, dass es den vorhergesagten Wert enthält.
Der folgende Code veranschaulicht das Erstellen eines Diagramms mit den folgenden Funktionen:
#Datensatz definieren
data <- mtcars[ , c("mpg", "disp")]
#Erstellen Sie ein einfaches lineares Regressionsmodell
model <- lm(mpg ~ disp, data = mtcars)
#Modell verwenden, um Vorhersageintervalle zu erstellen
predictions <- predict(model, interval = "predict")
#Datensatz erstellen, der Originaldaten zusammen mit Vorhersageintervallen enthält
all_data <- cbind(data, predictions)
#Laden der ggplot2 Bibliothek
library(ggplot2)
#Plot erstellen
ggplot(all_data, aes(x = disp, y = mpg)) + #x- und y-Achsen-Variablen definieren
geom_point() + #Streudiagramm-Punkte hinzufügen
stat_smooth(method = lm) + #Kondidenzbänder
geom_line(aes(y = lwr), col = "coral2", linetype = "dashed") +
geom_line(aes(y = upr), col = "coral2", linetype = "dashed")
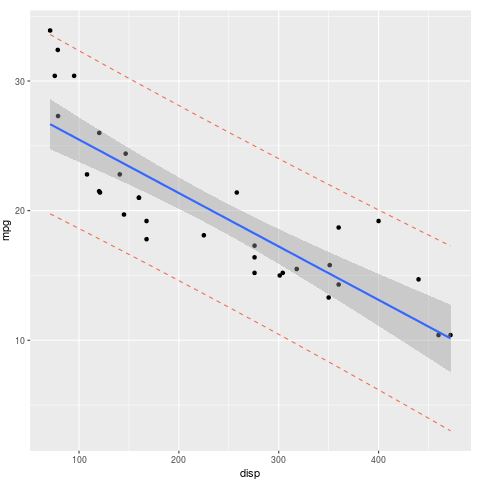
Ein Vorhersageintervall erfasst die Unsicherheit um einen einzelnen Wert. Ein Konfidenzintervall erfasst die Unsicherheit um die vorhergesagten Mittelwerte. Somit ist ein Vorhersageintervall immer breiter als ein Konfidenzintervall für denselben Wert.
Sie sollten ein Vorhersageintervall verwenden, wenn Sie an bestimmten individuellen Vorhersagen interessiert sind, da ein Konfidenzintervall einen zu engen Wertebereich erzeugt, was zu einer größeren Wahrscheinlichkeit führt, dass das Intervall nicht den wahren Wert enthält.
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
Die logistische Regression ist eine statistische Methode, die wir verwenden, um ein Regressionsmodell anzupassen, wenn die Antwortvariable binär ist.
Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz …