
Bei der Interpolation wird ein unbekannter Wert einer Funktion zwischen zwei bekannten Werten geschätzt.
Wenn zwei bekannte Werte (x 1 , y 1 ) und (x 2 , y 2 ) gegeben sind, können …
Das Gebiet des maschinellen Lernens enthält eine Vielzahl von Algorithmen, mit denen Daten verstanden werden können. Diese Algorithmen können in eine von zwei Kategorien eingeteilt werden:
1. Überwachte Lernalgorithmen: (engl. supervised learning) Umfasst die Erstellung eines Modells zur Schätzung oder Vorhersage einer Ausgabe basierend auf einer oder mehreren Eingaben.
2. Unüberwachte Lernalgorithmen: (engl. unsupervised learning) Umfasst das Finden von Struktur und Beziehungen aus Eingaben. Es gibt keine "Überwachungs" -Ausgabe.
In diesem Tutorial wird der Unterschied zwischen diesen beiden Arten von Algorithmen zusammen mit mehreren Beispielen erläutert.
Ein überwachter Lernalgorithmus kann verwendet werden, wenn wir eine oder mehrere erklärende Variablen (X 1 , X 2 , X 3 ,…, X p ) und eine Antwortvariable (Y) haben und wir eine Funktion finden möchten, die die Beziehung zwischen beschreibt die erklärenden Variablen und die Antwortvariable:
Y = f (X) + ε
Dabei steht f für systematische Informationen, die X über Y liefert, und wobei ε ein von X unabhängiger Zufallsfehlerterm mit einem Mittelwert von Null ist.
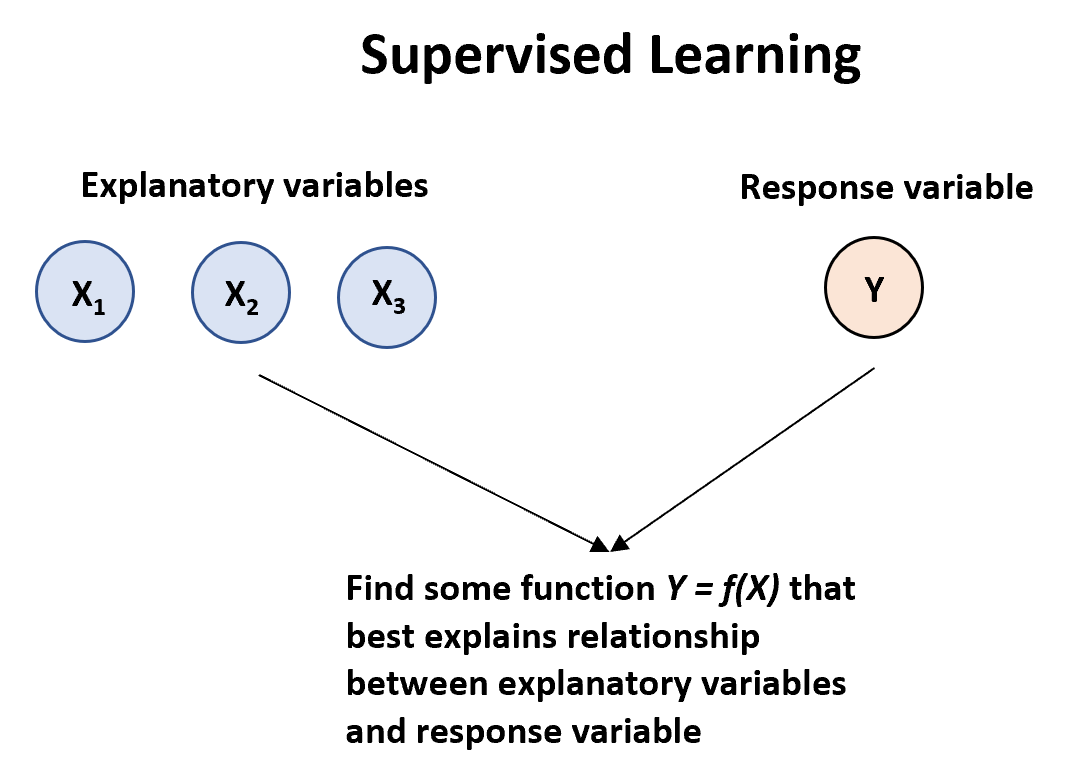
Es gibt zwei Haupttypen von überwachten Lernalgorithmen:
1. Regression: Die Ausgabevariable ist kontinuierlich (z. B. Gewicht, Größe, Zeit usw.)
2. Klassifizierung: Die Ausgabevariable ist kategorisch (z. B. männlich oder weiblich, bestanden oder nicht bestanden, gutartig oder bösartig usw.)
Es gibt zwei Hauptgründe, warum wir überwachte Lernalgorithmen verwenden:
1. Vorhersage: Wir verwenden häufig eine Reihe von erklärenden Variablen, um den Wert einer Antwortvariablen vorherzusagen (z. B. anhand der Quadratmeterzahl und der Anzahl der Schlafzimmer, um den Eigenheimpreis vorherzusagen).
2. Schlussfolgerung: Wir könnten daran interessiert sein zu verstehen, wie eine Antwortvariable beeinflusst wird, wenn sich der Wert der erklärenden Variablen ändert (z. B. wie stark steigt der Eigenheimpreis im Durchschnitt, wenn die Anzahl der Schlafzimmer um eins steigt?).
Abhängig davon, ob unser Ziel Inferenz oder Vorhersage (oder eine Mischung aus beiden) ist, können wir verschiedene Methoden zur Schätzung der Funktion **f verwenden**. Beispielsweise bieten lineare Modelle eine einfachere Interpretation, aber nichtlineare Modelle, die schwer zu interpretieren sind, bieten möglicherweise eine genauere Vorhersage.
Hier ist eine Liste der am häufigsten verwendeten überwachten Lernalgorithmen: - Lineare Regression- Logistische Regression - Lineare Diskriminanzanalyse - Quadratische Diskriminanzanalyse - Entscheidungsbäume - Naive Bayes - Support-Vektor-Maschinen - Neuronale Netze
Ein unüberwachter Lernalgorithmus kann verwendet werden, wenn wir eine Liste von Variablen haben (X 1 , X 2 , X 3 , ..., X p ) und einfach die zugrunde liegenden Strukturen oder Muster in den Daten finden möchten.
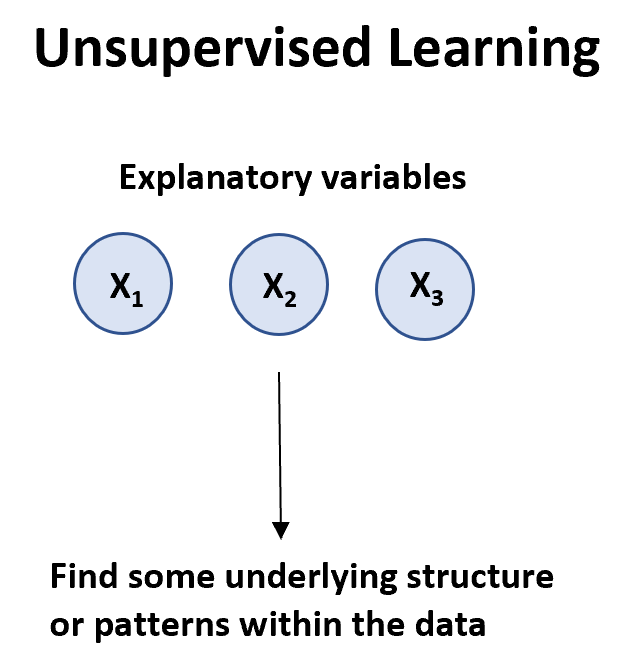
Es gibt zwei Haupttypen von unüberwachten Lernalgorithmen:
1. Clustering: Mit diesen Arten von Algorithmen versuchen wir, „Cluster“ von Beobachtungen in einem Datensatz zu finden, die einander ähnlich sind. Dies wird häufig im Einzelhandel verwendet, wenn ein Unternehmen Kundencluster mit ähnlichen Einkaufsgewohnheiten identifizieren möchte, um spezifische Marketingstrategien für bestimmte Kundencluster zu entwickeln.
2. Assoziation: Mit diesen Arten von Algorithmen versuchen wir, „Regeln“ zu finden, mit denen Assoziationen gezeichnet werden können. Beispielsweise können Einzelhändler einen Assoziationsalgorithmus entwickeln, der besagt: "Wenn ein Kunde Produkt X kauft, kauft er höchstwahrscheinlich auch Produkt Y."
Hier ist eine Liste der am häufigsten verwendeten unüberwachten Lernalgorithmen: - Hauptkomponentenanalyse - K-bedeutet Clustering - Clusterbildung von K-Medoiden - Hierarchisches Clustering - Apriori-Algorithmus
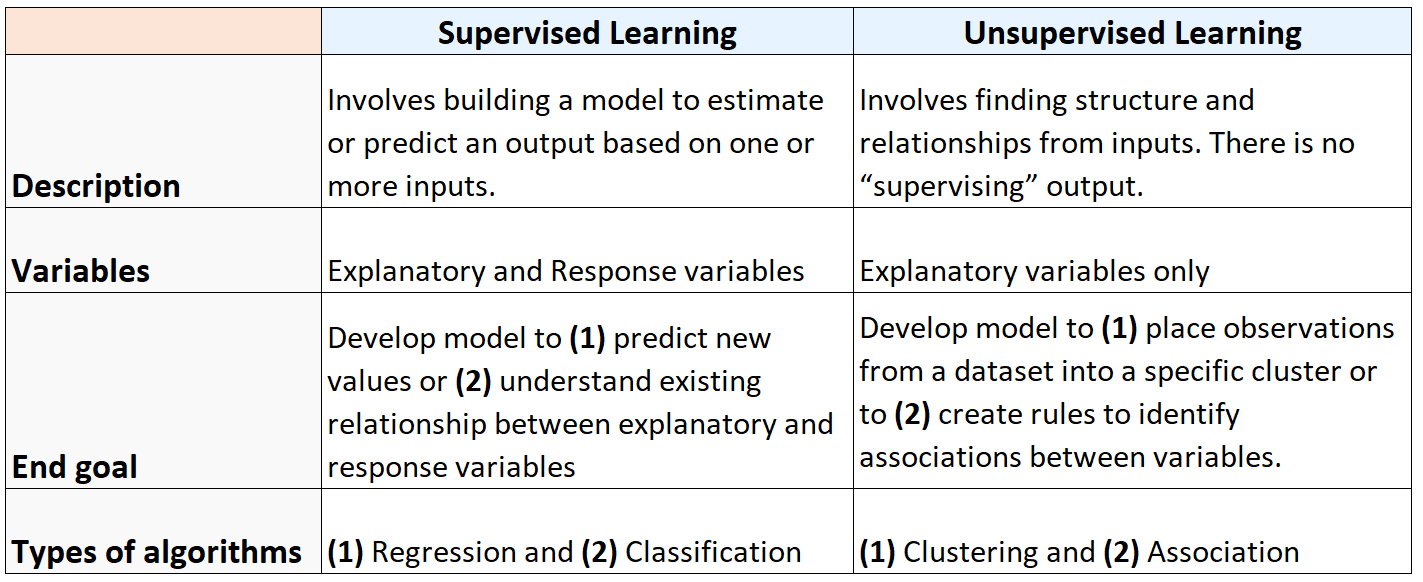
Die folgende Tabelle fasst die Unterschiede zwischen überwachten und unüberwachten Lernalgorithmen zusammen:
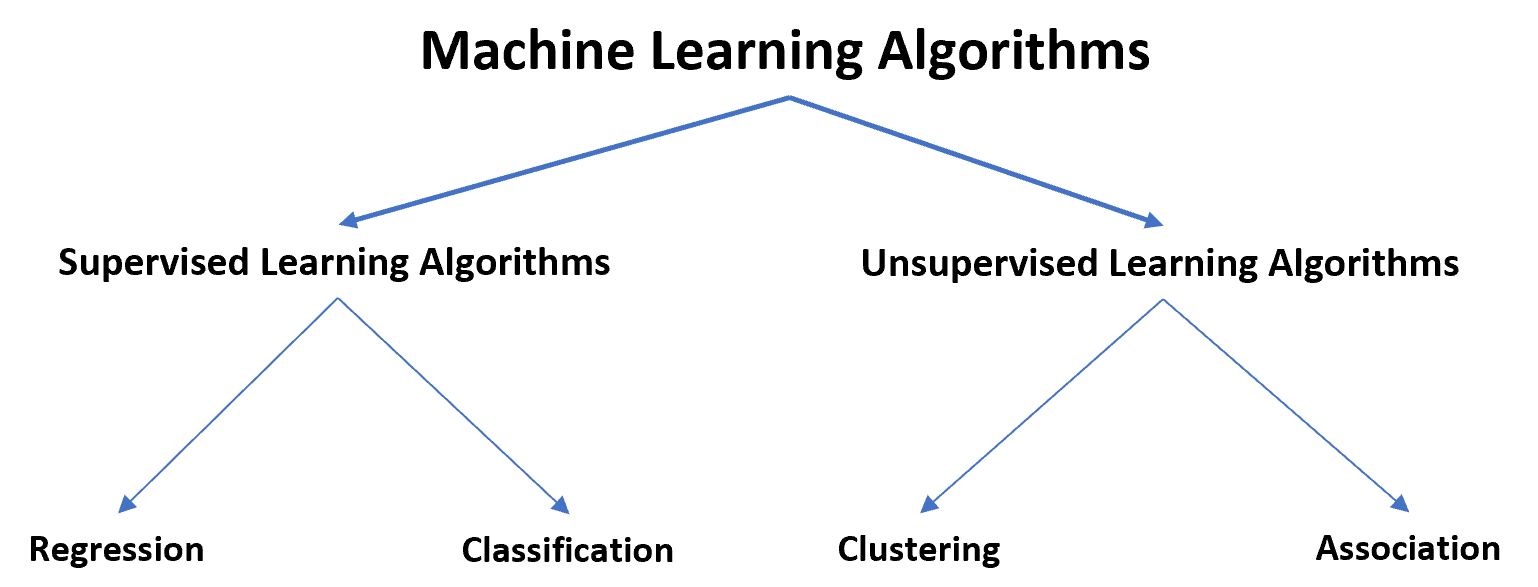
Das folgende Diagramm fasst die Arten von Algorithmen für maschinelles Lernen zusammen:
Bei der Interpolation wird ein unbekannter Wert einer Funktion zwischen zwei bekannten Werten geschätzt.
Wenn zwei bekannte Werte (x 1 , y 1 ) und (x 2 , y 2 ) gegeben sind, können …
Gelegentlich möchten Sie möglicherweise die 10 wichtigsten Werte in einer Liste in Excel finden. Glücklicherweise ist dies mit der Funktion KGRÖSSTE(), die die folgende Syntax verwendet, einfach zu bewerkstelligen:
KGRÖSSTE …