
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
- K: Die Anzahl der Modellparameter …
Die logistische Regression ist eine statistische Methode, mit der wir ein Regressionsmodell anpassen, wenn die Antwortvariable binär ist. Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz passt, können wir die folgenden zwei Metriken betrachten:
Eine einfache Möglichkeit, diese beiden Metriken zu visualisieren, besteht darin, eine ROC-Kurve zu erstellen. Hierbei handelt es sich um ein Diagramm, das die Sensitivität und Spezifität eines logistischen Regressionsmodells anzeigt.
In diesem Tutorial wird erklärt, wie Sie eine ROC-Kurve in Stata erstellen und interpretieren.
In diesem Beispiel verwenden wir einen Datensatz namens lbw, der die folgenden Variablen für 189 Mütter enthält:
Wir werden ein logistisches Regressionsmodell an die Daten anpassen, wobei Alter und Rauchen als erklärende Variablen und niedriges Geburtsgewicht als Antwortvariable verwendet werden. Anschließend erstellen wir eine ROC-Kurve, um zu analysieren, wie gut das Modell zu den Daten passt.
Schritt 1: Laden und Anzeigen der Daten.
Laden Sie die Daten mit dem folgenden Befehl:
use http://www.stata-press.com/data/r13/lbw
Verschaffen Sie sich mit dem folgenden Befehl ein schnelles Verständnis des Datensatzes:
summarize
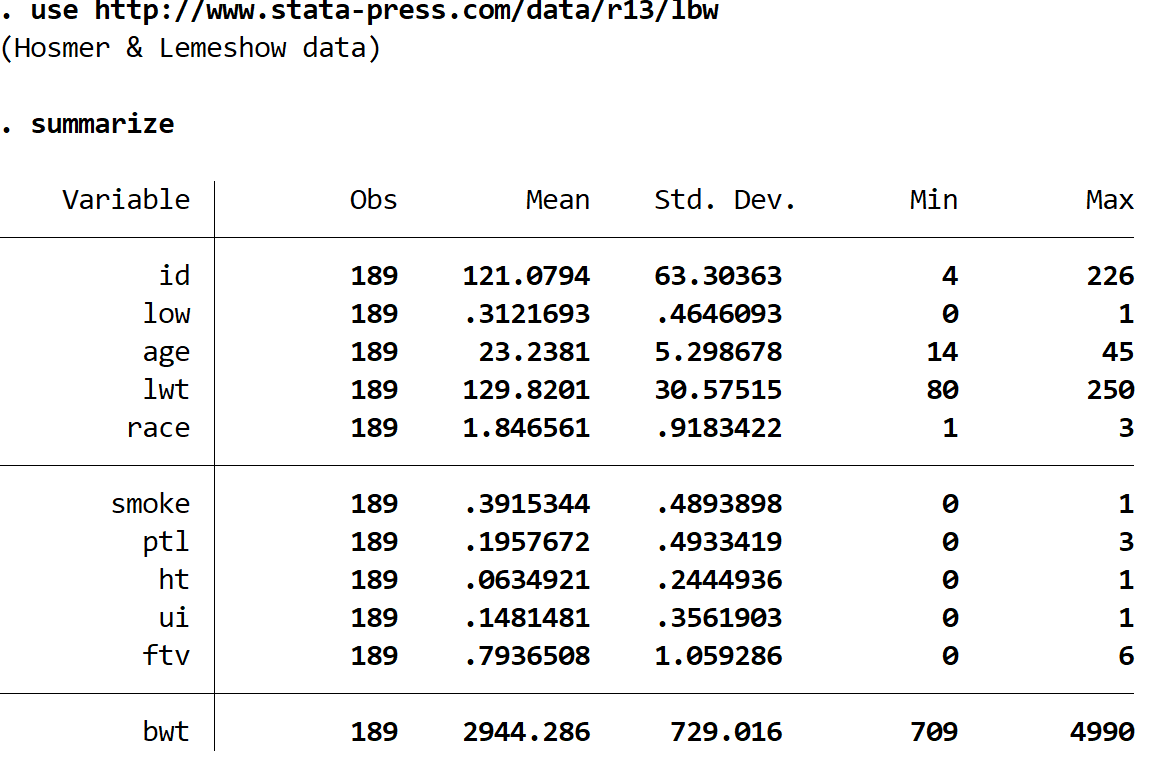
Der Datensatz enthält 11 verschiedene Variablen, aber die einzigen drei, die uns wichtig sind, sind Niedrig, Alter und Rauch.
Schritt 2: Passen Sie das logistische Regressionsmodell an.
Verwenden Sie den folgenden Befehl, um das logistische Regressionsmodell anzupassen:
logit low age smoke
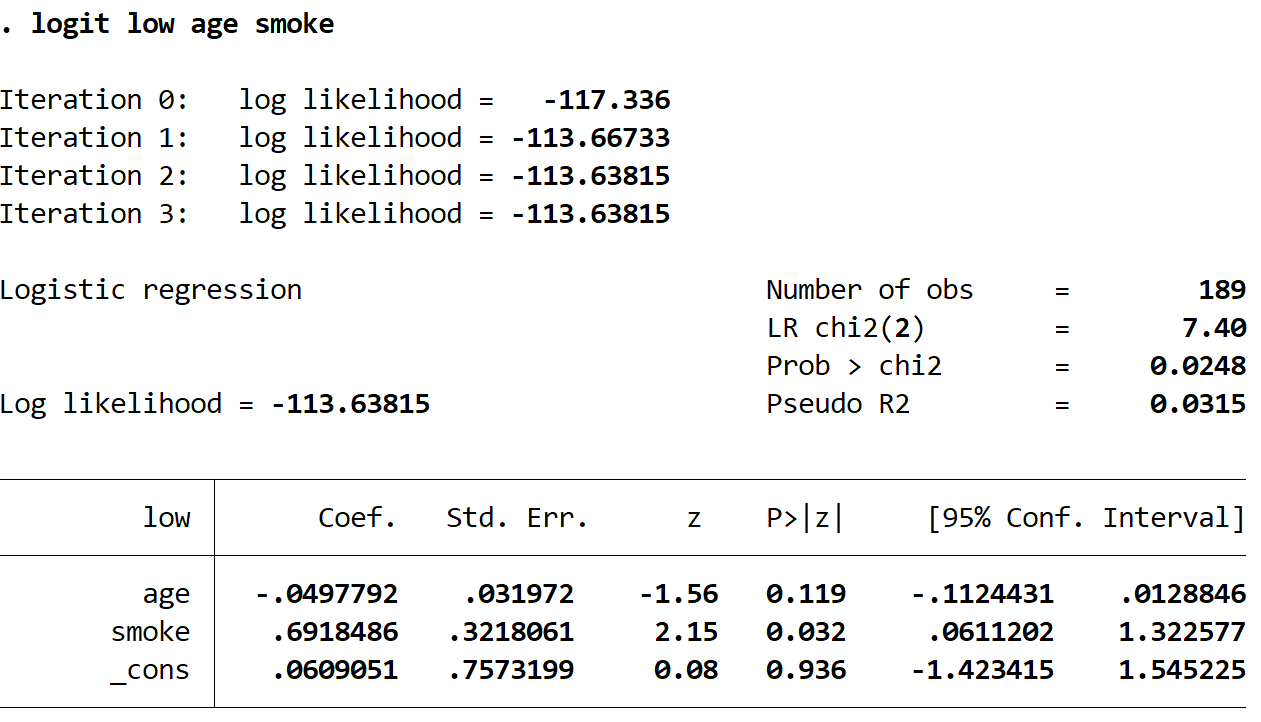
Schritt 3: Erstellen Sie die ROC-Kurve.
Wir können die ROC-Kurve für das Modell mit dem folgenden Befehl erstellen:
lroc
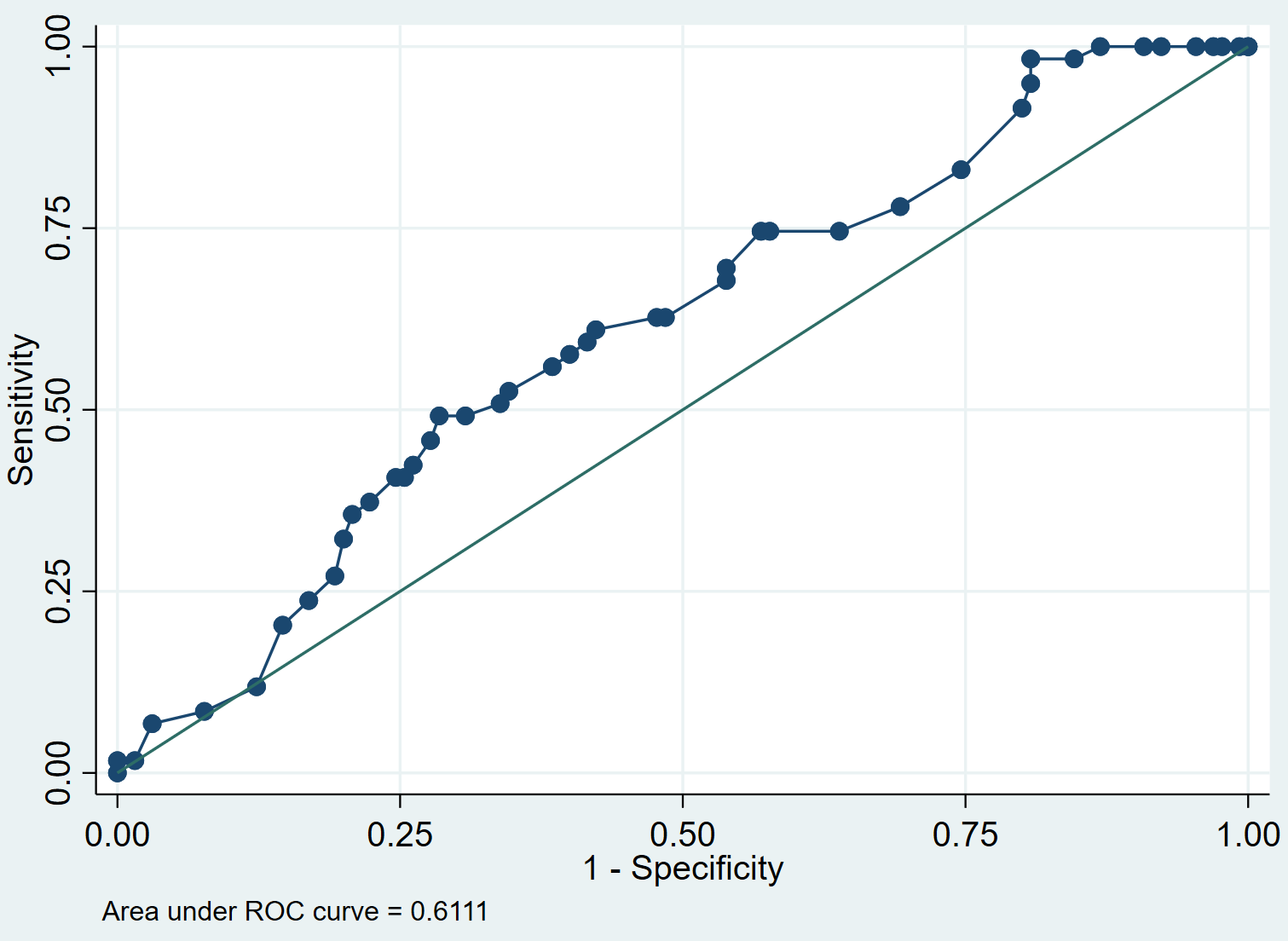
Schritt 4: Interpretieren Sie die ROC-Kurve.
Wenn wir ein logistisches Regressionsmodell anpassen, kann es verwendet werden, um die Wahrscheinlichkeit zu berechnen, dass eine bestimmte Beobachtung ein positives Ergebnis hat, basierend auf den Werten der Prädiktorvariablen.
Um zu bestimmen, ob eine Beobachtung als positiv eingestuft werden soll, können wir einen Schnittpunkt so wählen, dass Beobachtungen mit einer angepassten Wahrscheinlichkeit über dem Schnittpunkt als positiv und Beobachtungen mit einer angepassten Wahrscheinlichkeit unter dem Schnittpunkt als negativ eingestuft werden.
Angenommen, wir wählen den Schnittpunkt als 0,5. Dies bedeutet, dass für jede Beobachtung mit einer angepassten Wahrscheinlichkeit von mehr als 0,5 ein positives Ergebnis vorhergesagt wird, während für jede Beobachtung mit einer angepassten Wahrscheinlichkeit von weniger als oder gleich 0,5 ein negatives Ergebnis vorhergesagt wird.
Die ROC-Kurve zeigt uns die Werte der Empfindlichkeit gegenüber der 1-Spezifität, wenn sich der Wert des Grenzwerts von 0 auf 1 bewegt. Ein Modell mit hoher Empfindlichkeit und hoher Spezifität hat eine ROC-Kurve, die sich an die obere linke Ecke des Diagramms. Ein Modell mit geringer Empfindlichkeit und geringer Spezifität weist eine Kurve auf, die nahe an der 45-Grad-Diagonalen liegt.
Die AUC (Area under Curve) gibt uns eine Vorstellung davon, wie gut das Modell zwischen positiven und negativen Ergebnissen unterscheiden kann. Die AUC kann zwischen 0 und 1 liegen. Je höher die AUC, desto besser kann das Modell die Ergebnisse korrekt klassifizieren. In unserem Beispiel sehen wir, dass die AUC 0,6111 beträgt.
Wir können AUC verwenden, um die Leistung von zwei oder mehr Modellen zu vergleichen. Das Modell mit der höheren AUC ist das Modell mit der besten Leistung.
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
Die logistische Regression ist eine statistische Methode, die wir verwenden, um ein Regressionsmodell anzupassen, wenn die Antwortvariable binär ist.
Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz …