
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
- K: Die Anzahl der Modellparameter …
Ein Residuendiagramm ist ein Diagrammtyp, bei dem die angepassten Werte gegen die Residuenwerte für ein Regressionsmodell angezeigt werden. Diese Art von Diagramm wird häufig verwendet, um zu bewerten, ob ein lineares Regressionsmodell für einen bestimmten Datensatz geeignet ist oder nicht, und um die Heteroskedastizität von Residuen zu überprüfen.
In diesem Tutorial wird erläutert, wie Sie in Python ein Residuendiagramm für ein lineares Regressionsmodell erstellen.
In diesem Beispiel verwenden wir einen Datensatz, der die Attribute von 10 Basketballspielern beschreibt:
import numpy as np
import pandas as pd
# Datensatz erstellen
df = pd.DataFrame({'rating': [90, 85, 82, 88, 94, 90, 76, 75, 87, 86],
'points': [25, 20, 14, 16, 27, 20, 12, 15, 14, 19],
'assists': [5, 7, 7, 8, 5, 7, 6, 9, 9, 5],
'rebounds': [11, 8, 10, 6, 6, 9, 6, 10, 10, 7]})
# Datensatz anzeigen
df
rating points assists rebounds
0 90 25 5 11
1 85 20 7 8
2 82 14 7 10
3 88 16 8 6
4 94 27 5 6
5 90 20 7 9
6 76 12 6 6
7 75 15 9 10
8 87 14 9 10
9 86 19 5 7
Angenommen, wir passen ein einfaches lineares Regressionsmodell an, bei dem Punkte als Prädiktorvariable und die Bewertung als Antwortvariable verwendet werden:
# Notwendige Bibliotheken importieren
import matplotlib.pyplot as plt
import statsmodels.api as sm
from statsmodels.formula.api import ols
# Einfaches lineares Regressionsmodell anpassen
model = ols('rating ~ points', data=df).fit()
# Modellzusammenfassung anzeigen
print(model.summary())
Mit der Funktion plot_regress_exog() aus der Bibliothek statsmodels können wir ein Residuum gegen ein angepasstes Diagramm erstellen:
# Größe definieren
fig = plt.figure(figsize=(12,8))
# Regressionsdiagramme erstellen
fig = sm.graphics.plot_regress_exog(model, 'points', fig=fig)
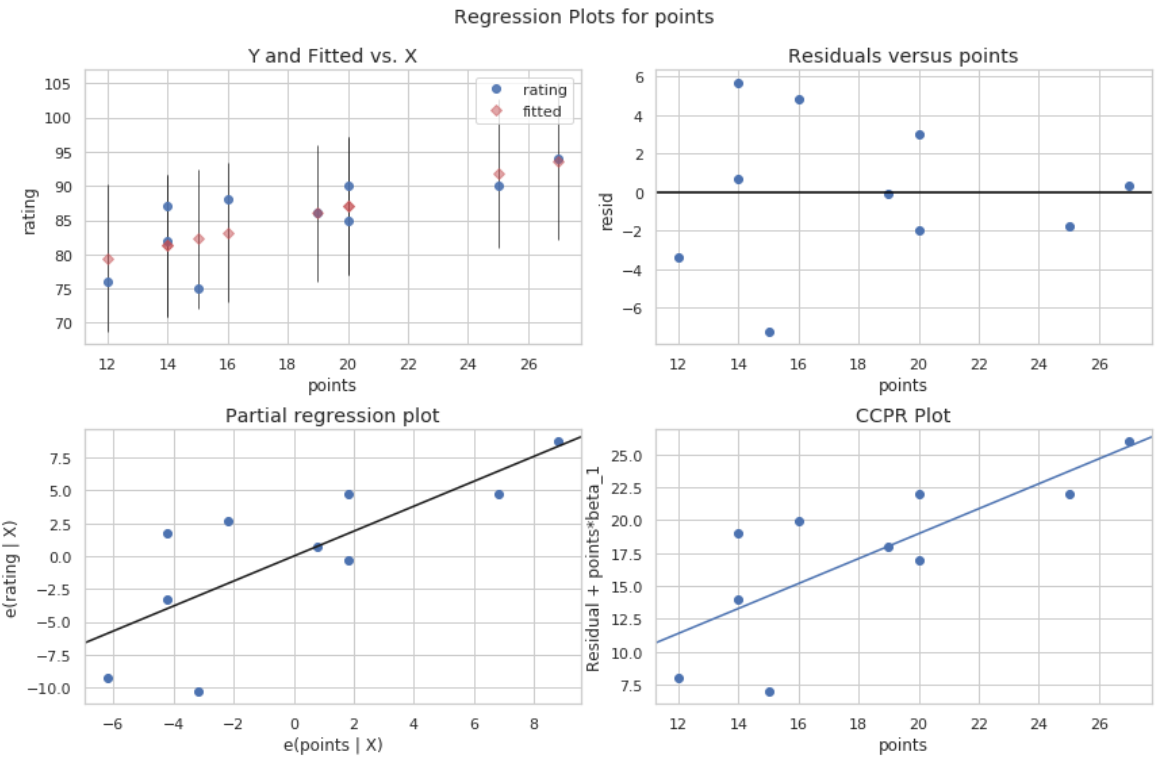
Es werden vier Parzellen erstellt. Die in der oberen rechten Ecke ist das verbleibende vs. angepasste Diagramm. Die x-Achse auf diesem Plot zeigt die tatsächlichen Werte für die Prädiktorvariable Punkte und die y-Achse zeigt das Residuum für diesen Wert.
Da die Residuen zufällig um Null gestreut zu sein scheinen, ist dies ein Hinweis darauf, dass Heteroskedastizität kein Problem mit der Prädiktorvariablen ist.
Angenommen, wir passen stattdessen ein multiples lineares Regressionsmodell an, bei dem Assists und Rebounds als Prädiktorvariable und Rating als Antwortvariable verwendet werden:
# Mehrere lineare Regressionsmodelle anpassen
model = ols('rating ~ assists + rebounds', data=df).fit()
# Modellzusammenfassung anzeigen
print(model.summary())
Mit der Funktion plot_regress_exog() aus der statsmodels Bibliothek können wir erneut ein Residuum-Prädiktor-Diagramm für jeden einzelnen Prädiktor erstellen.
Im Folgenden sehen Sie beispielsweise, wie das Residuum-Prädiktor-Diagramm für die Prädiktorvariablen- Assists aussieht:
# Residuum vs. Prädiktor-Plot für 'Assists' erstellen
fig = plt.figure(figsize=(12,8))
fig = sm.graphics.plot_regress_exog(model, 'assists', fig=fig)
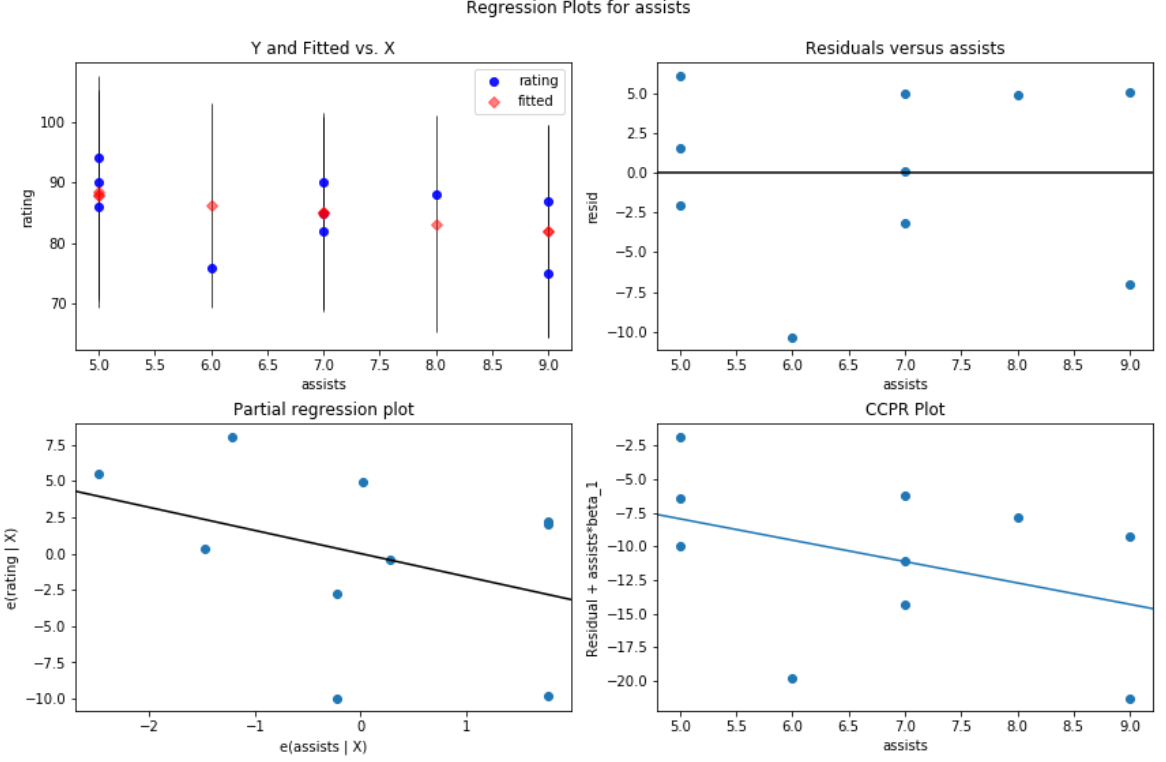
Und so sieht das Residuum-Prädiktor-Diagramm für die Rebounds der Prädiktorvariablen aus:
# Residuum vs. Prädiktor-Plot für 'Assists' erstellen
fig = plt.figure(figsize=(12,8))
fig = sm.graphics.plot_regress_exog(model, 'rebounds', fig=fig)

In beiden Darstellungen scheinen die Residuen zufällig um Null herum verstreut zu sein, was ein Hinweis darauf ist, dass Heteroskedastizität bei keiner der Prädiktorvariablen im Modell ein Problem darstellt.
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
Die logistische Regression ist eine statistische Methode, die wir verwenden, um ein Regressionsmodell anzupassen, wenn die Antwortvariable binär ist.
Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz …