
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
- K: Die Anzahl der Modellparameter …
Die einfache lineare Regression ist eine statistische Methode, mit der Sie die Beziehung zwischen zwei Variablen, x und y, verstehen können. Eine Variable x, ist als Prädiktorvariable bekannt. Die andere Variable y ist als Antwortvariable bekannt.
Angenommen, wir haben den folgenden Datensatz mit dem Gewicht und der Größe von sieben Personen:
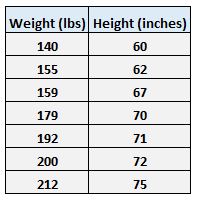
Das Gewicht (weight) sei die Prädiktorvariable und die Größe (height)die Antwortvariable.
Wenn wir diese beiden Variablen mithilfe eines Streudiagramms mit Gewicht auf der x-Achse und Höhe auf der y-Achse grafisch darstellen, würde dies folgendermaßen aussehen:
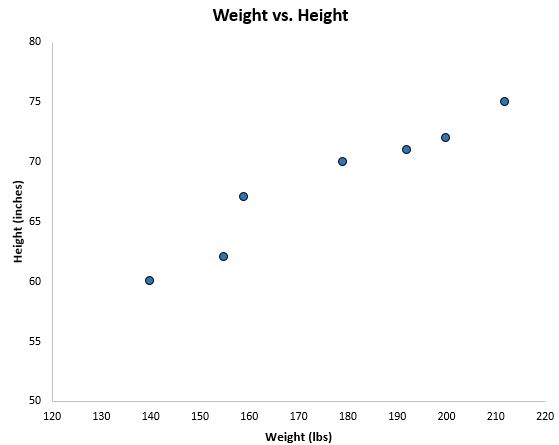
Aus dem Streudiagramm können wir deutlich erkennen, dass mit zunehmendem Gewicht auch die Größe tendenziell zunimmt. Um diese Beziehung zwischen Gewicht und Größe tatsächlich zu quantifizieren, müssen wir jedoch eine lineare Regression verwenden.
Mithilfe der linearen Regression können wir die Linie finden, die am besten zu unseren Daten passt:
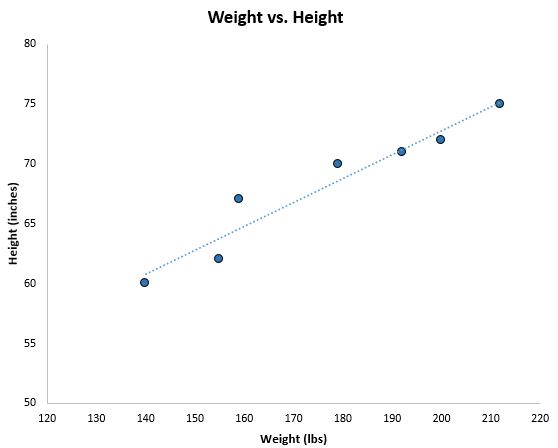
Die Formel für diese Linie der besten Anpassung lautet wie folgt:
ŷ = b 0 + b 1 x
Dabei ist ŷ der vorhergesagte Wert der Antwortvariablen, b 0 der y-Achsenabschnitt, b 1 der Regressionskoeffizient und x der Wert der Prädiktorvariablen.
In diesem Beispiel lautet die Linie der besten Anpassung:
height = 32,783 + 0,2001 * (weight)
Beachten Sie, dass die Datenpunkte in unserem Streudiagramm nicht immer genau auf die Linie der besten Anpassung fallen:
Diese Differenz zwischen dem Datenpunkt und der Linie wird als Residuum bezeichnet. Für jeden Datenpunkt können wir das Residuum dieses Punkts berechnen, indem wir die Differenz zwischen seinem tatsächlichen Wert und dem vorhergesagten Wert aus der Linie der besten Anpassung ziehen.
Erinnern Sie sich beispielsweise an das Gewicht und die Größe der sieben Personen in unserem Datensatz:
Die erste Person hat ein Gewicht von 140 Pfund. und eine Höhe von 60 Zoll.
Um die vorhergesagte Größe für diese Person herauszufinden, können wir ihr Gewicht in die Linie der Best-Fit-Gleichung einfügen:
height = 32,783 + 0,2001 * (weight)
Somit ist die vorhergesagte Größe dieses Individuums:
height = 32,783 + 0,2001 * (140)
height = 60,797 Zoll
Somit beträgt das Residuum für diesen Datenpunkt 60 – 60,797 = -0,797.
Wir können genau den gleichen Prozess verwenden, den wir oben verwendet haben, um das Residuum für jeden Datenpunkt zu berechnen. Berechnen wir zum Beispiel das Residuum für die zweite Person in unserem Datensatz:
Die zweite Person hat ein Gewicht von 155 Pfund. und eine Höhe von 62 Zoll.
Um die vorhergesagte Größe für diese Person herauszufinden, können wir ihr Gewicht in die Linie der Best-Fit-Gleichung einfügen:
height = 32,783 + 0,2001 * (Gewicht)
Somit ist die vorhergesagte Größe dieses Individuums:
height = 32,783 + 0,2001 * (155)
height = 63,7985 Zoll
Somit beträgt das Residuum für diesen Datenpunkt 62 – 63,7985 = -1,7985.
Mit der gleichen Methode wie in den beiden vorherigen Beispielen können wir die Residuen für jeden Datenpunkt berechnen:
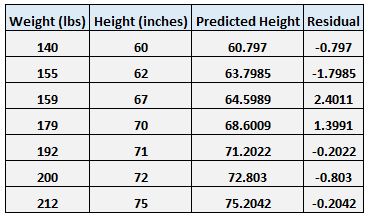
Beachten Sie, dass einige der Residuen positiv und andere negativ sind. Wenn wir alle Residuen addieren, addieren sie sich zu Null. Dies liegt daran, dass die lineare Regression die Linie findet, die die gesamten quadratischen Residuen minimiert, weshalb die Linie die Daten perfekt durchläuft, wobei einige der Datenpunkte über der Linie und einige unter der Linie liegen.
Denken Sie daran, dass ein Residuum einfach der Abstand zwischen dem tatsächlichen Datenwert und dem Wert ist, der durch die Regressionslinie der besten Anpassung vorhergesagt wird. So sehen diese Entfernungen auf einem Streudiagramm visuell aus:

Beachten Sie, dass einige der Residuen größer als andere sind. Außerdem sind einige der Residuen positiv und andere negativ, wie bereits erwähnt.
Bei der Berechnung der Residuen geht es darum zu sehen, wie gut die Regressionslinie zu den Daten passt. Größere Residuen zeigen an, dass die Regressionslinie schlecht zu den Daten passt, d.h. die tatsächlichen Datenpunkte fallen nicht in die Nähe der Regressionslinie. Kleinere Residuen zeigen an, dass die Regressionslinie besser zu den Daten passt, d.h. die tatsächlichen Datenpunkte liegen nahe an der Regressionslinie.
Ein nützlicher Diagrammtyp zur gleichzeitigen Visualisierung aller Residuen ist ein Residuendiagramm. Ein Residuendiagramm (oder Residualplot) ist ein Diagrammtyp, der die vorhergesagten Werte gegen die Residuenwerte für ein Regressionsmodell anzeigt. Diese Art von Diagramm wird häufig verwendet, um zu bewerten, ob ein lineares Regressionsmodell für einen bestimmten Datensatz geeignet ist oder nicht, und um die Heteroskedastizität von Residuen zu überprüfen.
In diesem Tutorial erfahren Sie, wie Sie ein Residuenplot für ein einfaches lineares Regressionsmodell in Excel erstellen.
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
Die logistische Regression ist eine statistische Methode, die wir verwenden, um ein Regressionsmodell anzupassen, wenn die Antwortvariable binär ist.
Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz …