
Bei der Interpolation wird ein unbekannter Wert einer Funktion zwischen zwei bekannten Werten geschätzt.
Wenn zwei bekannte Werte (x 1 , y 1 ) und (x 2 , y 2 ) gegeben sind, können …
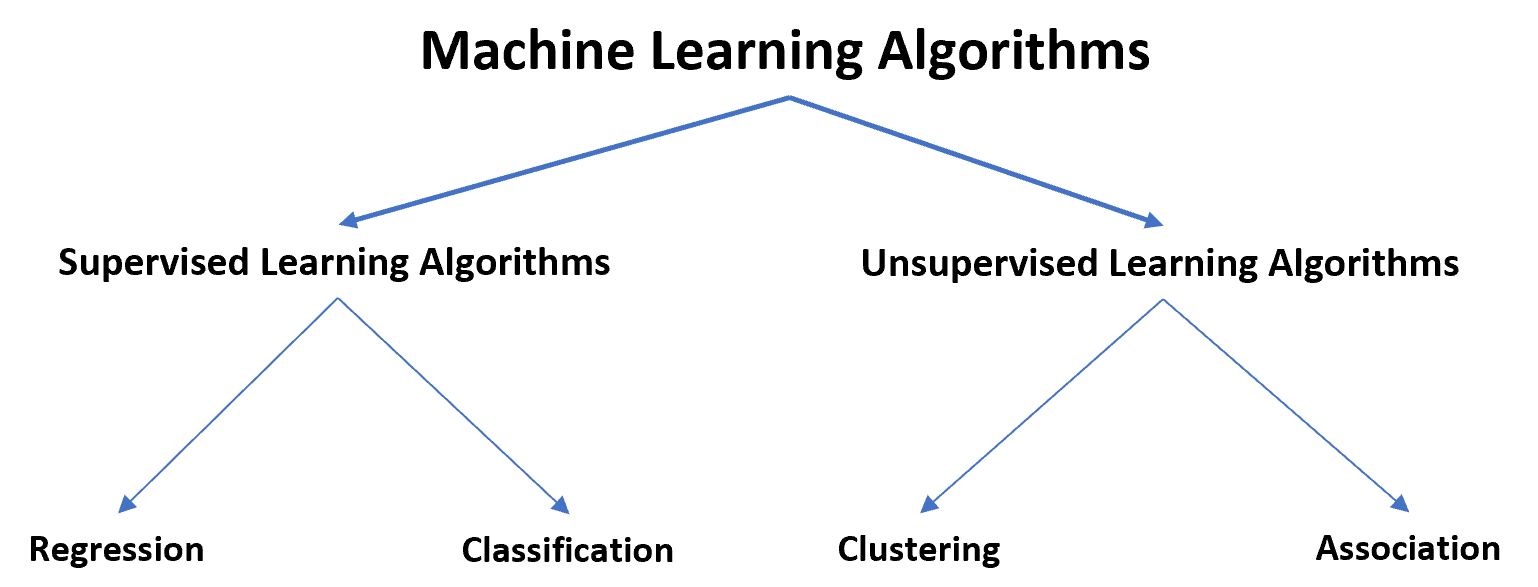
Algorithmen für maschinelles Lernen können in zwei verschiedene Typen unterteilt werden: überwachte und unüberwachte Lernalgorithmen.
 {static}/images/supervised4.png
{static}/images/supervised4.png
Überwachte Lernalgorithmen können weiter in zwei Typen eingeteilt werden:
1. Regression: Die Antwortvariable ist kontinuierlich.
Die Antwortvariable könnte beispielsweise sein:
In jedem Fall versucht ein Regressionsmodell, eine kontinuierliche Größe vorherzusagen.
Regressionsbeispiel:
Angenommen, wir haben einen Datensatz, der drei Variablen für 100 verschiedene Häuser enthält: Quadratmeterzahl, Anzahl der Badezimmer und Verkaufspreis. Wir könnten ein Regressionsmodell anpassen, das Quadratmeterzahl und Anzahl der Badezimmer als erklärende Variablen und den Verkaufspreis als Antwortvariable verwendet. Wir könnten dieses Modell dann verwenden, um den Verkaufspreis eines Hauses basierend auf seiner Fläche und der Anzahl der Badezimmer vorherzusagen. Dies ist ein Beispiel für ein Regressionsmodell, da die Antwortvariable (Verkaufspreis) kontinuierlich ist.
Die gebräuchlichste Methode zur Messung der Genauigkeit eines Regressionsmodells ist die Berechnung des quadratischen Mittelwertfehlers (RMSE), einer Metrik, die angibt, wie weit unsere vorhergesagten Werte von unseren beobachteten Werten in einem Modell im Durchschnitt entfernt sind. Es wird berechnet als:
RMSE = √ [Σ (P i - O i ) 2 / n]
wo:
Je kleiner der RMSE ist, desto besser kann ein Regressionsmodell die Daten anpassen.
2. Klassifizierung: Die Antwortvariable ist kategorisch.
Beispielsweise könnte die Antwortvariable die folgenden Werte annehmen:
In jedem Fall versucht ein Klassifizierungsmodell, eine Klassenbezeichnung vorherzusagen.
Klassifizierungsbeispiel:
Angenommen, wir haben einen Datensatz, der drei Variablen für 100 verschiedene College-Basketballspieler enthält: Durchschnittspunkte pro Spiel, Divisionsstufe und ob sie in die NBA eingezogen wurden oder nicht. Wir könnten ein Klassifizierungsmodell anpassen, das Durchschnittspunkte pro Spiel und Divisionsstufe als erklärende Variablen und als Antwortvariable "entworfen" verwendet. Wir könnten dieses Modell dann verwenden, um vorherzusagen, ob ein bestimmter Spieler basierend auf seinen durchschnittlichen Punkten pro Spiel und Divisionsstufe in die NBA eingezogen wird oder nicht. Dies ist ein Beispiel für ein Klassifizierungsmodell, da die Antwortvariable ("entworfen") kategorisch ist. Das heißt, es kann nur Werte in zwei verschiedenen Kategorien annehmen: "Entwurf" oder "Nicht Entwurf".
Die gebräuchlichste Methode zur Messung der Genauigkeit eines Klassifizierungsmodells besteht darin, einfach den Prozentsatz der korrekten Klassifizierungen zu berechnen, die das Modell vornimmt:
Genauigkeit = Korrekte Klassifizierungen / insgesamte Klassifizierungen * 100%
Wenn ein Modell beispielsweise korrekt identifiziert, ob ein Spieler 88 von 100 möglichen Zeiten in die NBA eingezogen wird oder nicht, ist die Genauigkeit des Modells:
Genauigkeit = (88/100) * 100% = 88%
Je höher die Genauigkeit, desto besser kann ein Klassifizierungsmodell die Ergebnisse vorhersagen.
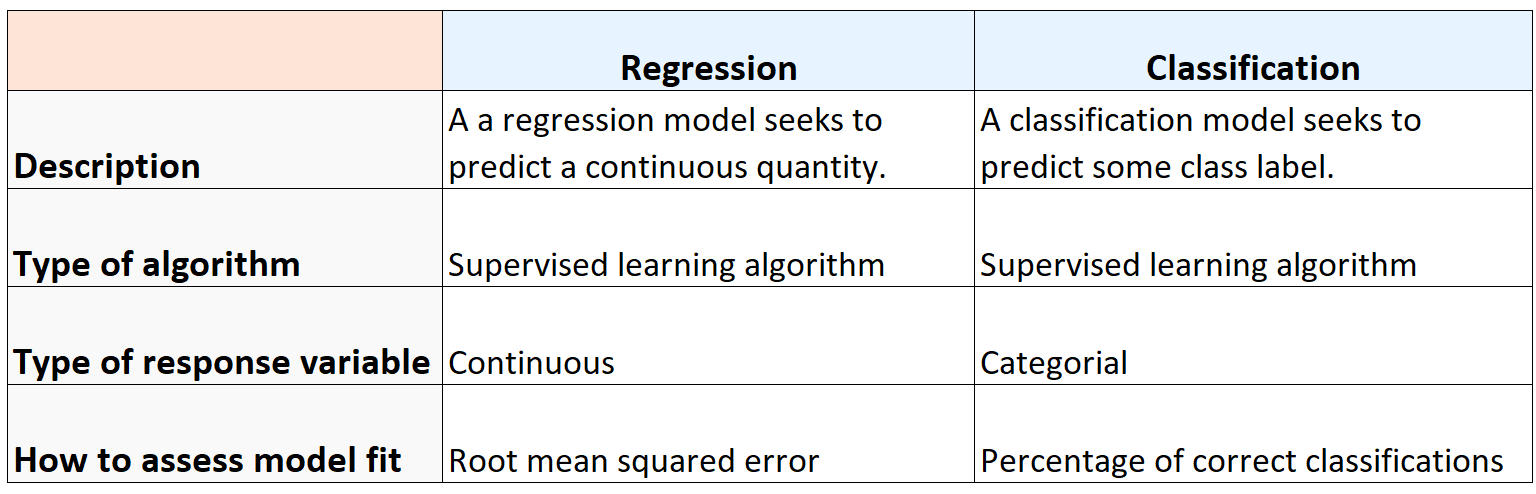
Regressions- und Klassifizierungsalgorithmen sind auf folgende Weise ähnlich:
Regressions- und Klassifizierungsalgorithmen unterscheiden sich auf folgende Weise:
Es ist erwähnenswert, dass ein Regressionsproblem in ein Klassifizierungsproblem umgewandelt werden kann, indem die Antwortvariable einfach in Buckets diskretisiert wird.
Angenommen, wir haben einen Datensatz, der drei Variablen enthält: Quadratmeterzahl, Anzahl der Badezimmer und Verkaufspreis.
Wir könnten ein Regressionsmodell erstellen, das Quadratmeter und Anzahl der Badezimmer verwendet, um den Verkaufspreis vorherzusagen.
Wir könnten den Verkaufspreis jedoch in drei verschiedene Klassen unterteilen:
Wir könnten dann Quadratmeter und Anzahl der Badezimmer als erklärende Variablen verwenden, um vorherzusagen, in welche Klasse (niedrig, mittel oder hoch) ein bestimmter Hausverkaufspreis fallen wird.
Dies wäre ein Beispiel für ein Klassifizierungsmodell, da wir versuchen, jedes Haus einer Klasse zuzuordnen.
Die folgende Tabelle fasst die Ähnlichkeiten und Unterschiede zwischen Regressions- und Klassifizierungsalgorithmen zusammen:
Bei der Interpolation wird ein unbekannter Wert einer Funktion zwischen zwei bekannten Werten geschätzt.
Wenn zwei bekannte Werte (x 1 , y 1 ) und (x 2 , y 2 ) gegeben sind, können …
Gelegentlich möchten Sie möglicherweise die 10 wichtigsten Werte in einer Liste in Excel finden. Glücklicherweise ist dies mit der Funktion KGRÖSSTE(), die die folgende Syntax verwendet, einfach zu bewerkstelligen:
KGRÖSSTE …