
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
- K: Die Anzahl der Modellparameter …
Die lineare Regression ist eine Methode, mit der wir die Beziehung zwischen einer oder mehreren Prädiktorvariablen und einer Antwortvariablen verstehen können.
Wenn wir eine lineare Regression durchführen, sind wir normalerweise daran interessiert, den Mittelwert der Antwortvariablen zu schätzen.
Wir könnten jedoch stattdessen eine Methode verwenden, die als Quantilregression bekannt ist, um einen beliebigen Quantil- oder Perzentilwert des Antwortwerts wie das 70. Perzentil, das 90. Perzentil, das 98. Perzentil usw. zu schätzen.
Dieses Tutorial enthält ein schrittweises Beispiel für die Verwendung dieser Funktion zur Durchführung der Quantilregression in Python.
Zuerst laden wir die erforderlichen Pakete und Funktionen:
import numpy as np
import pandas as pd
import statsmodels.api as sm
import statsmodels.formula.api as smf
import matplotlib.pyplot as plt
In diesem Beispiel erstellen wir einen Datensatz, der die untersuchten Stunden und die Prüfungsergebnisse für 100 Studenten an einer Universität enthält:
#Machen Sie dieses Beispiel reproduzierbar
np.random.seed(0)
# Datensatz erstellen
obs = 100
hours = np.random.uniform(1, 10, obs)
score = 60 + 2*hours + np.random.normal(loc=0, scale=.45*hours, size=100)
df = pd.DataFrame({'hours': hours, 'score': score})
# Die ersten fünf Zeilen anzeigen
df.head()
hours score
0 5.939322 68.764553
1 7.436704 77.888040
2 6.424870 74.196060
3 5.903949 67.726441
4 4.812893 72.849046
Als nächstes passen wir ein Quantil-Regressionsmodell an, bei dem die untersuchten Stunden als Prädiktorvariable und der Prüfungswert als Antwortvariable verwendet werden.
Wir werden das Modell verwenden, um das erwartete 90. Perzentil der Prüfungsergebnisse basierend auf der Anzahl der untersuchten Stunden vorherzusagen:
# Passen Sie das Modell an
model = smf.quantreg('score ~ hours', df).fit(q=0.9)
# Modellzusammenfassung anzeigen
print(model.summary())
QuantReg Regression Results
==============================================================================
Dep. Variable: score Pseudo R-squared: 0.6057
Model: QuantReg Bandwidth: 3.822
Method: Least Squares Sparsity: 10.85
Date: Tue, 29 Dec 2020 No. Observations: 100
Time: 15:41:44 Df Residuals: 98
Df Model: 1
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 59.6104 0.748 79.702 0.000 58.126 61.095
hours 2.8495 0.128 22.303 0.000 2.596 3.103
==============================================================================
Aus der Ausgabe können wir die geschätzte Regressionsgleichung sehen:
90. Perzentil der Prüfungsergebnisse = 59.6104 + 2.8495 * (Stunden)
Beispielsweise wird erwartet, dass das 90. Perzentil der Punktzahl für alle Schüler, die 8 Stunden lernen, 82,4 beträgt:
90. Perzentil der Prüfungsergebnisse = 59,6104 + 2,8495 * (8) = 82,4.
Die Ausgabe zeigt auch die oberen und unteren Konfidenzgrenzen für den Schnittpunkt und die variablen Stunden des Prädiktors an.
Wir können die Ergebnisse der Regression auch visualisieren, indem wir ein Streudiagramm mit der angepassten Quantil-Regressionsgleichung erstellen, die dem Diagramm überlagert ist:
# Diagramm und Achse definieren
fig, ax = plt.subplots(figsize=(8, 6))
# y Werte abfragen
get_y = lambda a, b: a + b * hours
y = get_y(model.params['Intercept'], model.params['hours'])
# Datenpunkte mit überlagerter Quantil-Regressionsgleichung plotten
ax.plot(hours, y, color='black')
ax.scatter(hours, score, alpha=.3)
ax.set_xlabel('Hours Studied', fontsize=14)
ax.set_ylabel('Exam Score', fontsize=14)
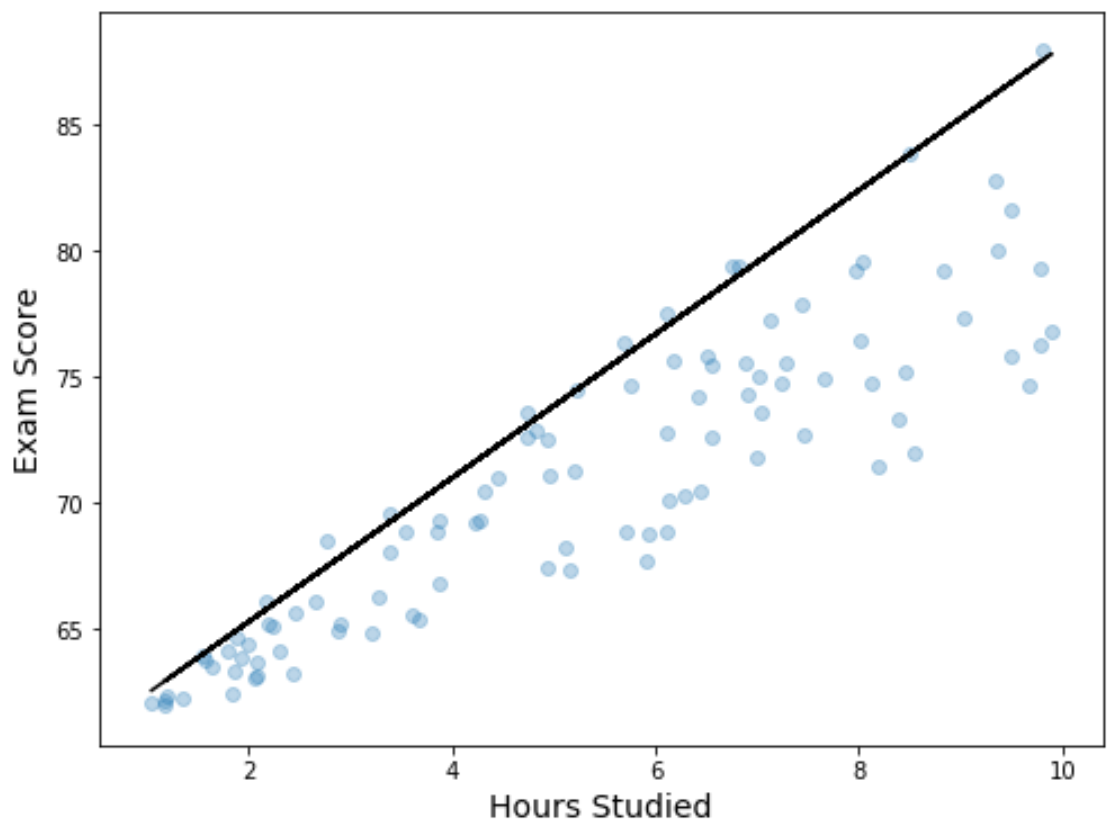
Beachten Sie im Gegensatz zu einer einfachen linearen Regressionslinie, dass diese angepasste Linie nicht die „Linie der besten Anpassung“ für die Daten darstellt. Stattdessen wird das geschätzte 90. Perzentil auf jeder Ebene der Prädiktorvariablen durchlaufen.
So führen Sie eine einfache lineare Regression in Python durch
So führen Sie eine quadratische Regression in Python durch
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
Die logistische Regression ist eine statistische Methode, die wir verwenden, um ein Regressionsmodell anzupassen, wenn die Antwortvariable binär ist.
Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz …