
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
- K: Die Anzahl der Modellparameter …
Die Regression ist eine statistische Technik, mit der wir die Beziehung zwischen einer oder mehreren Prädiktorvariablen und einer Antwortvariablen erklären können. Die häufigste Art der Regression ist die lineare Regression, die wir verwenden, wenn die Beziehung zwischen der Prädiktorvariablen und der Antwortvariablen linear ist.
Das heißt, wenn die Prädiktorvariable zunimmt, nimmt auch die Antwortvariable tendenziell zu. Beispielsweise können wir ein lineares Regressionsmodell verwenden, um die Beziehung zwischen der Anzahl der untersuchten Stunden (Prädiktorvariable) und der Punktzahl zu beschreiben, die ein Schüler bei einer Prüfung erhält (Antwortvariable).
Manchmal ist die Beziehung zwischen einer Prädiktorvariablen und einer Antwortvariablen jedoch nicht linear. Ein häufiger Typ einer nichtlinearen Beziehung ist eine quadratische Beziehung, die in einem Diagramm wie ein U oder ein umgedrehtes U aussehen kann.
Das heißt, wenn die Prädiktorvariable zunimmt, nimmt auch die Antwortvariable tendenziell zu, aber nach einem bestimmten Punkt beginnt die Antwortvariable abzunehmen, wenn die Prädiktorvariable weiter zunimmt.
Zum Beispiel können wir ein quadratisches Regressionsmodell verwenden, um die Beziehung zwischen der Anzahl der Arbeitsstunden und dem gemeldeten Zufriedenheitsgrad einer Person zu beschreiben. Je mehr ein Mensch arbeitet, desto erfüllter fühlt er sich vielleicht, aber sobald er eine bestimmte Schwelle erreicht hat, führt mehr Arbeit tatsächlich zu Stress und verminderter Zufriedenheit. In diesem Fall würde ein quadratisches Regressionsmodell besser zu den Daten passen als ein lineares Regressionsmodell.
Lassen Sie uns ein Beispiel für die quadratische Regression in Excel durchgehen.
Angenommen, wir haben Daten zur Anzahl der pro Woche geleisteten Arbeitsstunden und zum gemeldeten Zufriedenheitsgrad (auf einer Skala von 0 bis 100) für 16 verschiedene Personen:
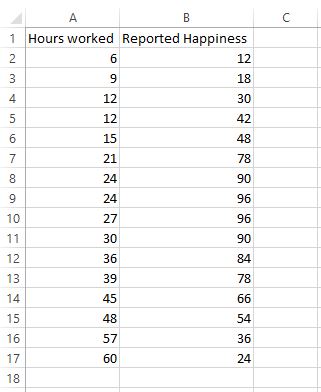
Lassen Sie uns zunächst ein Streudiagramm erstellen, um festzustellen, ob die lineare Regression ein geeignetes Modell für die Anpassung an die Daten ist.
Markieren Sie die Zellen A2: B17. Anschließend klicken Sie auf die Registerkarte Einfügen entlang der oberen Band, klicken Sie dann auf Punkt (X Y) im Bereich Diagramme. Dadurch wird ein Streudiagramm der Daten erstellt:
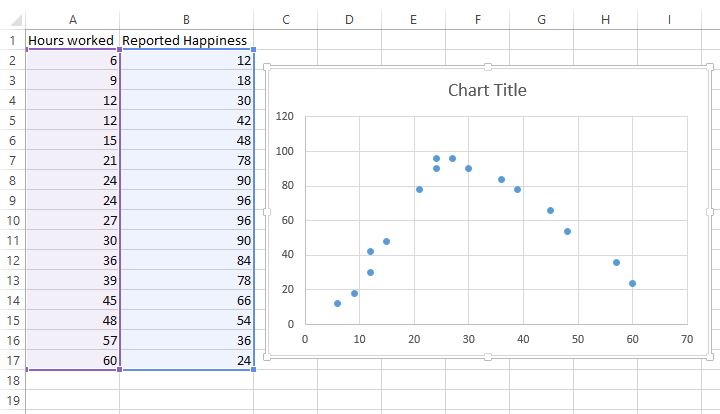
Es ist leicht zu erkennen, dass die Beziehung zwischen den geleisteten Arbeitsstunden und der gemeldeten Zufriedenheit nicht linear ist. Tatsächlich folgt es einer U-Form, was es zu einem perfekten Kandidaten für die quadratische Regression macht.
Bevor wir das quadratische Regressionsmodell an die Daten anpassen, müssen wir eine neue Spalte für die quadratischen Werte unserer Prädiktorvariablen erstellen.
Markieren Sie zunächst alle Werte in Spalte B und ziehen Sie sie in Spalte C.
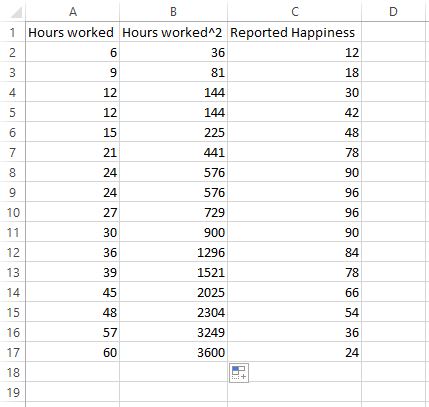
Geben Sie als nächstes die Formel =A2^2 in Zelle B2 ein. Dies ergibt den Wert 36. Klicken Sie anschließend auf die untere rechte Ecke von Zelle B2 und ziehen Sie die Formel nach unten, um die verbleibenden Zellen in Spalte B auszufüllen.
Als nächstes werden wir das quadratische Regressionsmodell anpassen.
Klicken Sie oben im Menüband auf Daten und dann ganz rechts auf die Option Datenanalyse. Wenn diese Option nicht angezeigt wird, müssen Sie zuerst das kostenlose Analysis ToolPak installieren.
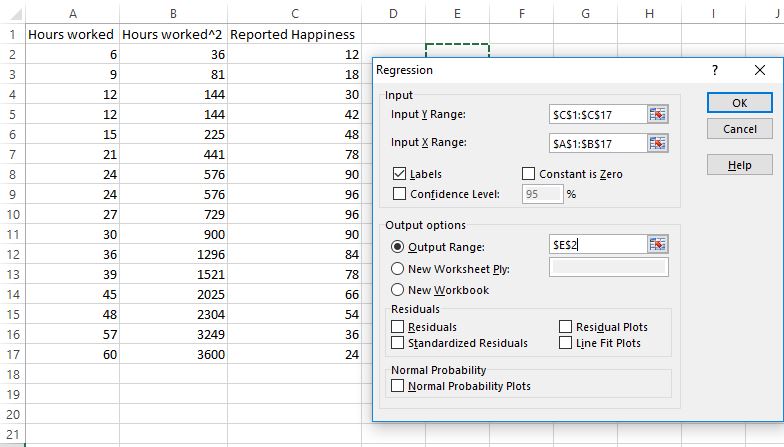
Sobald Sie auf Datenanalyse klicken, wird ein Feld angezeigt. Klicken Sie auf Regression und dann auf OK.

Geben Sie als Nächstes die folgenden Werte in das daraufhin angezeigte Feld Regression ein. Klicken Sie dann auf OK.
Die folgenden Ergebnisse werden angezeigt:
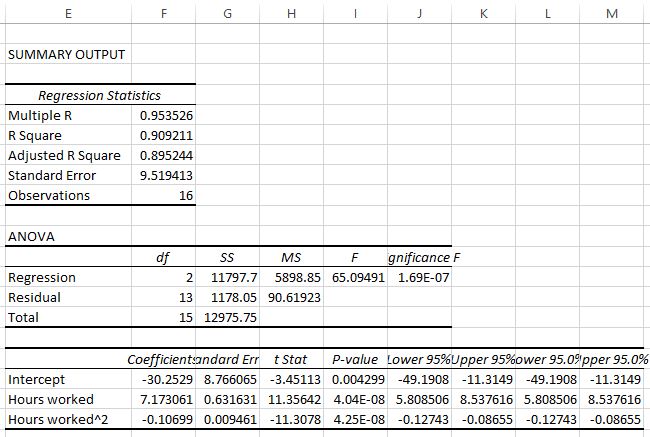
So interpretieren Sie verschiedene Zahlen aus der Ausgabe:
R Square: Dies wird auch als Bestimmungskoeffizient bezeichnet und ist der Anteil der Varianz in der Antwortvariablen, der durch die Prädiktorvariablen erklärt werden kann. In diesem Beispiel beträgt das R-Quadrat 0,9092, was darauf hinweist, dass 90,92% der Varianz der gemeldeten Zufriedenheitsniveaus durch die Anzahl der geleisteten Arbeitsstunden und die Anzahl der geleisteten Arbeitsstunden erklärt werden können ^ 2.
Standard Error: Der Standardfehler der Regression ist der durchschnittliche Abstand, um den die beobachteten Werte von der Regressionslinie fallen. In diesem Beispiel fallen die beobachteten Werte durchschnittlich um 9,519 Einheiten von der Regressionslinie ab.
F Statistic: Die F-Statistik wird als Regressions-MS / Residuen-MS berechnet. Diese Statistik gibt an, ob das Regressionsmodell besser zu den Daten passt als ein Modell, das keine unabhängigen Variablen enthält. Im Wesentlichen wird geprüft, ob das Regressionsmodell insgesamt nützlich ist. Wenn keine der Prädiktorvariablen im Modell statistisch signifikant ist, ist die F-Gesamtstatistik im Allgemeinen auch statistisch nicht signifikant. In diesem Beispiel ist die F-Statistik 65,09 und der entsprechende p-Wert ist <0,0001. Da dieser p-Wert weniger als 0,05 beträgt, ist das Regressionsmodell insgesamt signifikant.
Regression coefficients: Die Regressionskoeffizienten in der letzten Tabelle geben uns die Zahlen an, die zum Schreiben der geschätzten Regressionsgleichung erforderlich sind:
y hat = b 0 + b 1 x 1 + b 2 x 12
In diesem Beispiel lautet die geschätzte Regressionsgleichung:
gemeldetes Zufriedenheitsniveau = -30,252 + 7,173 (geleistete Arbeitsstunden) -0,106 (geleistete Arbeitsstunden) 2
Wir können diese Gleichung verwenden, um das erwartete Zufriedenheitsniveau eines Individuums basierend auf seinen geleisteten Arbeitsstunden zu berechnen. Das erwartete Zufriedenheitsniveau von jemandem, der 30 Stunden pro Woche arbeitet, ist beispielsweise:
gemeldetes Zufriedenheitsniveau = -30,252 + 7,173 (30) -0,106 (30) 2 = 88,649.
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
Die logistische Regression ist eine statistische Methode, die wir verwenden, um ein Regressionsmodell anzupassen, wenn die Antwortvariable binär ist.
Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz …