
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
- K: Die Anzahl der Modellparameter …
Der Sinn der Regressionsanalyse besteht darin, die Beziehung zwischen einer oder mehreren Prädiktorvariablen und einer Antwortvariablen zu verstehen.
Zum Beispiel könnte uns die Beziehung zwischen der Anzahl der untersuchten Stunden (Prädiktorvariable) und der Punktzahl der Abschlussprüfung (Antwortvariable) für einen bestimmten College-Kurs interessieren.
Oder wir interessieren uns für die Beziehung zwischen Alter (Prädiktorvariable) und Größe (Antwortvariable) für eine bestimmte Pflanzenart.
Wenn wir nur eine Prädiktorvariable und eine Antwortvariable haben, können wir eine einfache lineare Regression durchführen. Bevor wir ein Regressionsmodell erstellen, ist es oft sinnvoll, ein Streudiagramm der Daten zu erstellen, um festzustellen, ob tatsächlich eine lineare Beziehung zwischen dem Prädiktor und der Antwortvariablen besteht. Wenn die Beziehung linear ist, ist es sinnvoll, eine lineare Regression an den Datensatz anzupassen.
Angenommen, wir haben den folgenden Datensatz, der die Anzahl der Stunden und die Punktzahl der Abschlussprüfung für eine Klasse von 50 Schülern anzeigt:
#Seed setzen, um dieses Beispiel reproduzierbar zu machen
set.seed (1)
#Erstellen Sie ein Dataframe mit zwei Variablen: study_hours und final_score
data <- data.frame(study_hours = runif(50, 5, 15), final_score = 50)
data$final_score = data$final_score + data$study_hours*runif(50, 2, 3)
# Die ersten sechs Datenzeilen anzeigen
head(data)
# study_hours final_score
#1 7.655087 68.96639
#2 8.721239 74.95329
#3 10.728534 76.15721
#4 14.082078 81.61141
#5 7.016819 64.52958
#6 13.983897 79.35872
#Daten plotten mit study_hours auf der x-Achse und final_score auf der y-Achse
plot(data$study_hours, data$final_score) #scatterplot
abline(lm(final_score ~ study_hours, data = data), col = 'red') #regression line
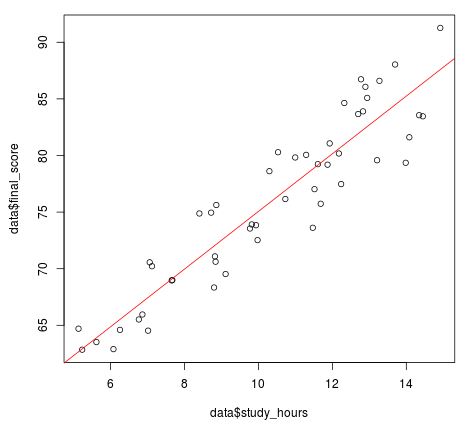
Wir können dem Streudiagramm entnehmen, dass es eine ziemlich starke positive lineare Beziehung zwischen den Studienstunden und der Punktzahl der Abschlussprüfung zu geben scheint: Je mehr Stunden ein Student studiert, desto höher ist die Punktzahl, die er tendenziell erhält.
Die einfache lineare Regressionslinie in der obigen Darstellung scheint recht gut zu diesem Datensatz zu passen, was sinnvoll ist, wenn man bedenkt, dass die wahre zugrunde liegende Beziehung zwischen den Studienstunden und dem Endergebnis linear ist.
Um zu sehen, wie gut ein lineares Regressionsmodell zu diesen Daten passt, können wir die Ausgabe des Modells anzeigen:
#Lineares Regressionsmodell anpassen
model <- lm(final_score ~ study_hours, data = data)
#Ansicht Modellausgabe
summary(model)
#Call:
#lm(formula = final_score ~ study_hours, data = data)
#
#Residuals:
# Min 1Q Median 3Q Max
#-5.8436 -2.1007 -0.3953 2.5287 4.6089
#
#Coefficients:
# Estimate Std. Error t value Pr(>|t|)
#(Intercept) 49.5840 1.5566 31.85 <2e-16 ***
#study_hours 2.5471 0.1459 17.46 <2e-16 ***
#---
#Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#
#Residual standard error: 2.78 on 48 degrees of freedom
#Multiple R-squared: 0.864, Adjusted R-squared: 0.8612
#F-statistic: 304.9 on 1 and 48 DF, p-value: < 2.2e-16
Wir können sehen, dass der Wert für das multiple R-Quadrat 0,864 beträgt. Diese Zahl stellt den Anteil der Varianz in der Antwortvariablen dar, der durch die Prädiktorvariable erklärt werden kann. Somit können 86,4% der Varianz in den Ergebnissen der Abschlussprüfung durch die Anzahl der untersuchten Stunden erklärt werden.
Außerdem beträgt der Wert für den verbleibenden Standardfehler 2,78. Diese Zahl stellt den durchschnittlichen Abstand dar, um den die beobachteten Werte von der Regressionslinie fallen. In diesem Beispiel fallen die beobachteten Werte also durchschnittlich nur um 2,78 Einheiten von der Regressionslinie ab.
Da das multiple r-Quadrat ziemlich hoch und der verbleibende Standardfehler ziemlich niedrig ist, zeigt dies, dass dieses einfache lineare Regressionsmodell gut zu den Daten passt.
Verwandt: Was ist ein guter R-Quadrat-Wert?
Allerdings haben nicht alle Prädiktor- und Antwortvariablen eine lineare Beziehung zueinander. Angenommen, die Beziehung zwischen Alter und Größe für eine bestimmte Pflanzenart ist nichtlinear.
Wenn die Pflanze jung ist, wächst sie sehr langsam. Dann, wenn es älter wird, erlebt es einen Wachstumsschub. Dann, wenn es weiter altert, beginnt es wieder sehr langsam zu wachsen.
Der folgende Datensatz zeigt diese Art der Beziehung zwischen Alter und Größe für eine bestimmte Pflanzenart:
#Seed setzen, um dieses Beispiel reproduzierbar zu machen
set.seed(1)
# Dataframe mit zwei Variablen erstellen: Alter (Tage) und Größe (cm)
data <- data.frame(age = round(runif(100, 1, 30), 0), height = 5)
data$height = data$height + ((data$age)^3)*runif(100, 2, 3)
# Die ersten sechs Datenzeilen anzeigen
head(data)
# age height
#1 9 1940.2937
#2 12 4071.3249
#3 18 13245.1572
#4 27 58910.0004
#5 7 908.2882
#6 27 43567.5757
#Daten plotten mit Alter auf der x-Achse und Höhe auf der y-Achse
plot(data$age, data$height) #Streudiagramm
abline(lm(height ~ age, data = data), col = 'red') #Regressionslinie
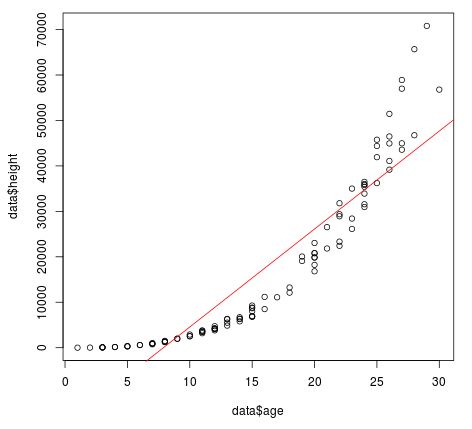
Die Beziehung zwischen Alter und Größe ist eindeutig nicht linear und wir können sehen, dass die lineare Regressionslinie sehr schlecht zu den Daten passt.
Um zu sehen, wie schlecht dieses Modell zu den Daten passt, können wir die Modellausgabe anzeigen:
#Lineares Regressionsmodell anpassen
model <- lm(height ~ age, data = data)
#Ansicht Modellausgabe
summary(model)
#Call:
#lm(formula = height ~ age, data = data)
#
#Residuals:
# Min 1Q Median 3Q Max
# -9678 -5639 -1689 3489 25296
#
#Coefficients:
# Estimate Std. Error t value Pr(>|t|)
#(Intercept) -17012.52 1688.95 -10.07 <2e-16 ***
#age 2156.03 94.96 22.70 <2e-16 ***
#---
#Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#
#Residual standard error: 7318 on 98 degrees of freedom
#Multiple R-squared: 0.8403, Adjusted R-squared: 0.8386
#F-statistic: 515.5 on 1 and 98 DF, p-value: < 2.2e-16
Wir können sehen, dass der Wert für das multiple R-Quadrat 0,8403 beträgt. Dies bedeutet, dass 84,03% der Varianz in der Pflanzenhöhe durch das Pflanzenalter erklärt werden können.
Obwohl das multiple r-Quadrat ziemlich hoch erscheint, kann es täuschen. Um ein besseres Verständnis der Anpassung des Modells zu erhalten, sollten wir uns den Wert für den verbleibenden Standardfehler ansehen, der 7318 beträgt. Dies zeigt, dass die beobachteten Werte durchschnittlich 7.318 Einheiten von der Regressionslinie abweichen. Diese Zahl ist ziemlich hoch und wenn wir dieses Modell verwenden würden, um Vorhersagen zu treffen, wären wir wahrscheinlich nicht sehr genau.
Darüber hinaus können wir visuell sehen, dass die Regressionslinie nicht gut zu den Daten im Diagramm passt und dass die wahre zugrunde liegende Beziehung zwischen Alter und Größe nicht genau linear ist.
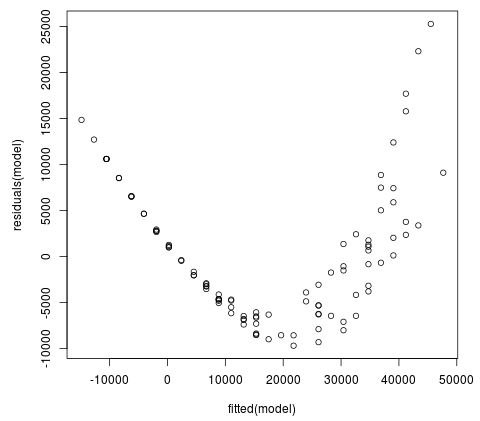
Eine einfache Darstellung der Residuen- / Anpassungswerte des Modells zeigt auch, dass die Residuen ein klares Muster aufweisen, was ein weiterer Hinweis darauf ist, dass das Modell nicht gut zu den Daten passt:
plot(fitted(model),residuals(model))
Da die wahre Beziehung zwischen Alter und Größe nichtlinear ist, können wir versuchen, ein polynomiales Regressionsmodell an die Daten anzupassen, das tendenziell viel besser zu den Kurven der Daten passt als ein lineares Modell.
Anstatt eine gerade Linie zu verwenden, um die Beziehung zwischen dem Prädiktor und der Antwortvariablen zu beschreiben, können wir durch eine polynomiale Regression eine nichtlineare Linie an die Daten anpassen.
Denken Sie insbesondere in diesem Beispiel daran, dass wir die folgende Zeile verwendet haben, um die Höhenwerte zu generieren:
data$height = data$height + ((data$age)^3)*runif(100, 2, 3)
Im wesentlichen durch Multiplikation mit einer Zufallszahl zwischen 2 und 3 haben wir die Variable age auf hoch drei genommen, dann ein wenig „Noise“ zu den Daten hinzugefügt.
Dies bedeutet, dass ein polynomiales Regressionsmodell dritter Ordnung wahrscheinlich besser zu den Daten passt als ein lineares Regressionsmodell.
Es gibt zwei Möglichkeiten, eine polynomiale Regression in R anzupassen:
poly_model <- lm(height ~ poly(age,3), data = data)
oder
poly_model <- lm(height ~ age + I(age^2) + I(age^3), data = data)
age, I(age^2) und I(age^3) werden jedoch korreliert und korrelierte Variablen können Probleme bei der Regression verursachen. Im Gegensatz dazu können Sie mit poly() dieses Problem vermeiden, indem Sie orthogonale Polynome erzeugen. Daher verwenden wir stattdessen diesen Ansatz.
#Polynom-Regressionsmodell anpassen
poly_model <- lm(height ~ poly(age,3), data = data)
#Ansicht Modellausgabe
summary(poly_model)
#Call:
#lm(formula = height ~ poly(age, 3), data = data)
#
#Residuals:
# Min 1Q Median 3Q Max
#-11596.4 -666.4 134.9 625.9 9944.6
#
#Coefficients:
# Estimate Std. Error t value Pr(>|t|)
#(Intercept) 17548.6 319.7 54.889 < 2e-16 ***
#poly(age, 3)1 166152.7 3197.1 51.970 < 2e-16 ***
#poly(age, 3)2 64684.8 3197.1 20.232 < 2e-16 ***
#poly(age, 3)3 9091.1 3197.1 2.844 0.00545 **
#---
#Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#
#Residual standard error: 3197 on 96 degrees of freedom
#Multiple R-squared: 0.9701, Adjusted R-squared: 0.9692
#F-statistic: 1039 on 3 and 96 DF, p-value: < 2.2e-16
Wir können sehen, dass der Wert für das multiple R-Quadrat 0,9701 beträgt, was viel höher ist als bei unserem linearen Modell. Sehen wir auch, dass der Wert für den Standardfehler der Residuen 3197 ist, das ist viel kleiner als der Wert von 7318 aus unserem linearen Modell.
Unser polynomiales Regressionsmodell dritter Ordnung hat die Anpassung gegenüber dem linearen Modell erheblich verbessert.
Bei Verwendung der Polynomregression ist es wichtig, eine Überanpassung der Daten zu vermeiden. Im Allgemeinen erzeugen Polynome höherer Ordnung immer engere Anpassungen und höhere r-Quadrat-Werte als Polynome niedrigerer Ordnung.
Leider kann dies nach einem bestimmten Punkt dazu führen, dass das Modell eher dem Rauschen (oder der „Zufälligkeit“) der Daten entspricht als der tatsächlichen zugrunde liegenden Beziehung zwischen dem Prädiktor und der Antwortvariablen. Dies kann zu Problemen führen, wenn das Modell zur Erstellung von Vorhersagen verwendet wird, und die Ergebnisse können irreführend sein.
Der Schlüssel zur Polynomregression besteht darin, eine Verbesserung gegenüber einem einfachen linearen Modell zu erzielen und gleichzeitig die mit einer Überanpassung verbundenen Fallstricke zu vermeiden.
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
Die logistische Regression ist eine statistische Methode, die wir verwenden, um ein Regressionsmodell anzupassen, wenn die Antwortvariable binär ist.
Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz …