
Das Resampling von Zeitreihendaten bedeutet, die Daten für einen neuen Zeitraum zusammenzufassen oder zu aggregieren.
Wir können die folgende grundlegende Syntax verwenden, um Zeitreihendaten in Python neu abzutasten:
#Finde die …Eine naive Prognose ist eine Prognose, bei der die Prognose für einen bestimmten Zeitraum einfach dem in der vorherigen Periode beobachteten Wert entspricht.
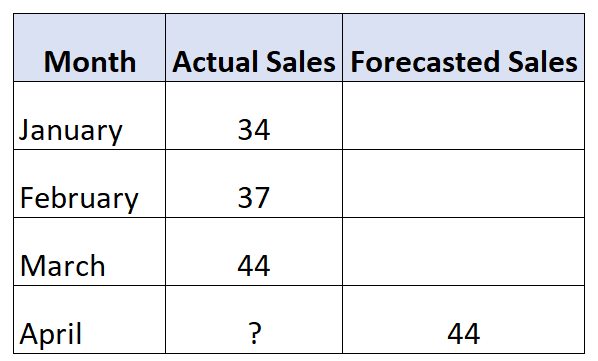
Angenommen, wir haben in den ersten drei Monaten des Jahres die folgenden Verkäufe eines bestimmten Produkts:

Die Umsatzprognose im April würde einfach dem tatsächlichen Umsatz des Vormonats März entsprechen:
Obwohl diese Methode einfach ist, funktioniert sie in der Praxis überraschend gut.
Dieses Tutorial bietet ein schrittweises Beispiel für die Durchführung naiver Prognosen in Excel.
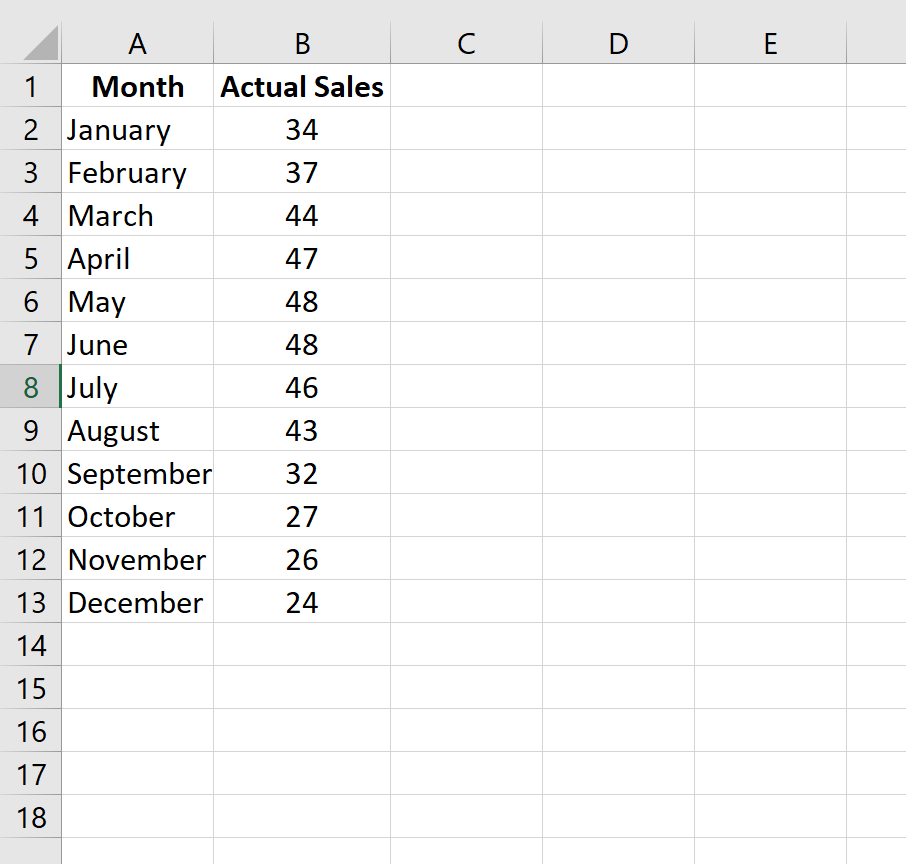
Zuerst geben wir die Verkaufsdaten für einen Zeitraum von 12 Monaten bei einem imaginären Unternehmen ein:
Als Nächstes verwenden wir die folgenden Formeln, um naive Prognosen für jeden Monat zu erstellen:

Schließlich müssen wir die Genauigkeit der Prognosen messen. Zwei gängige Metriken zur Messung der Genauigkeit sind:
Die folgende Abbildung zeigt, wie der mittlere absolute prozentuale Fehler berechnet wird:
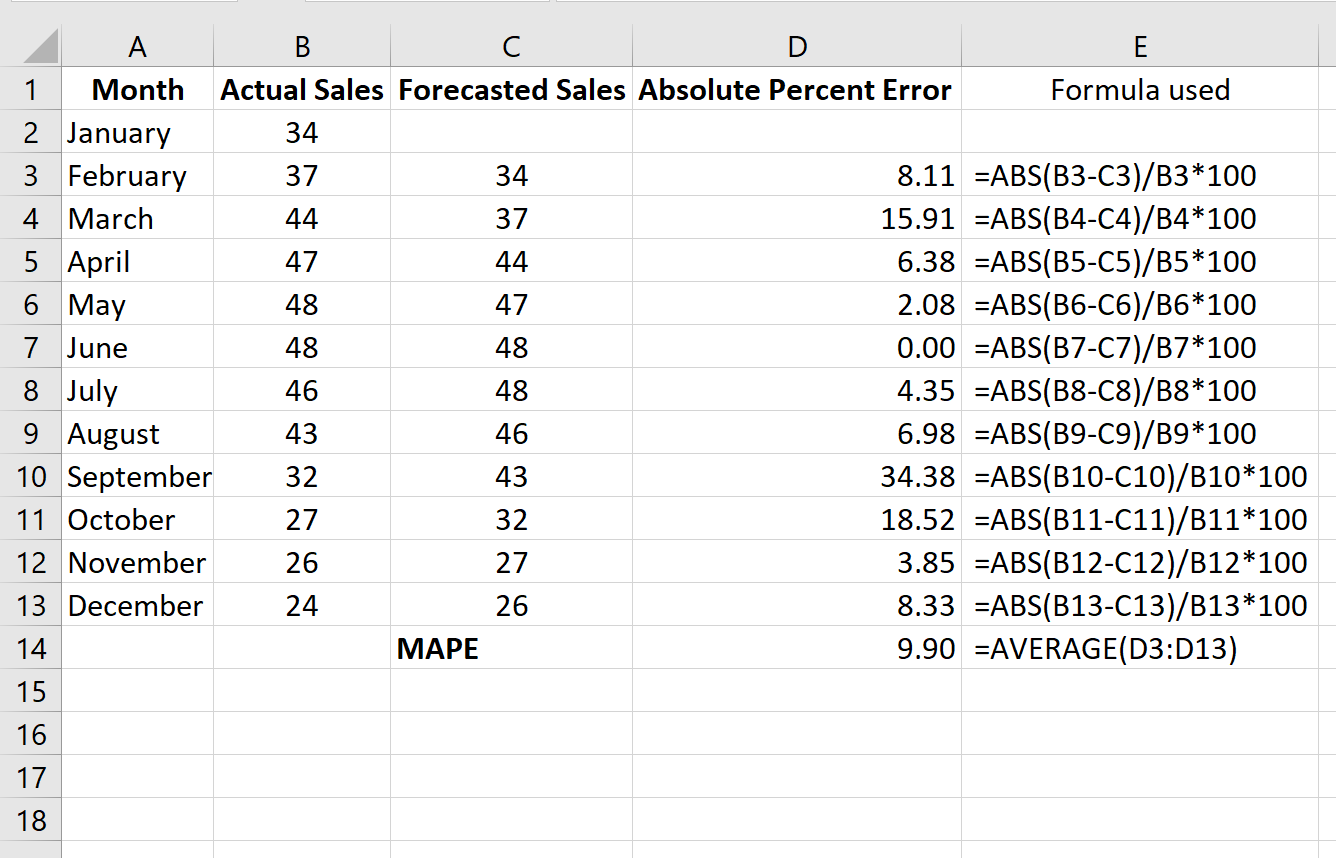
Der mittlere absolute prozentuale Fehler beträgt 9,9%.
Und das folgende Bild zeigt, wie die mittlere absolute Abweichung berechnet wird:
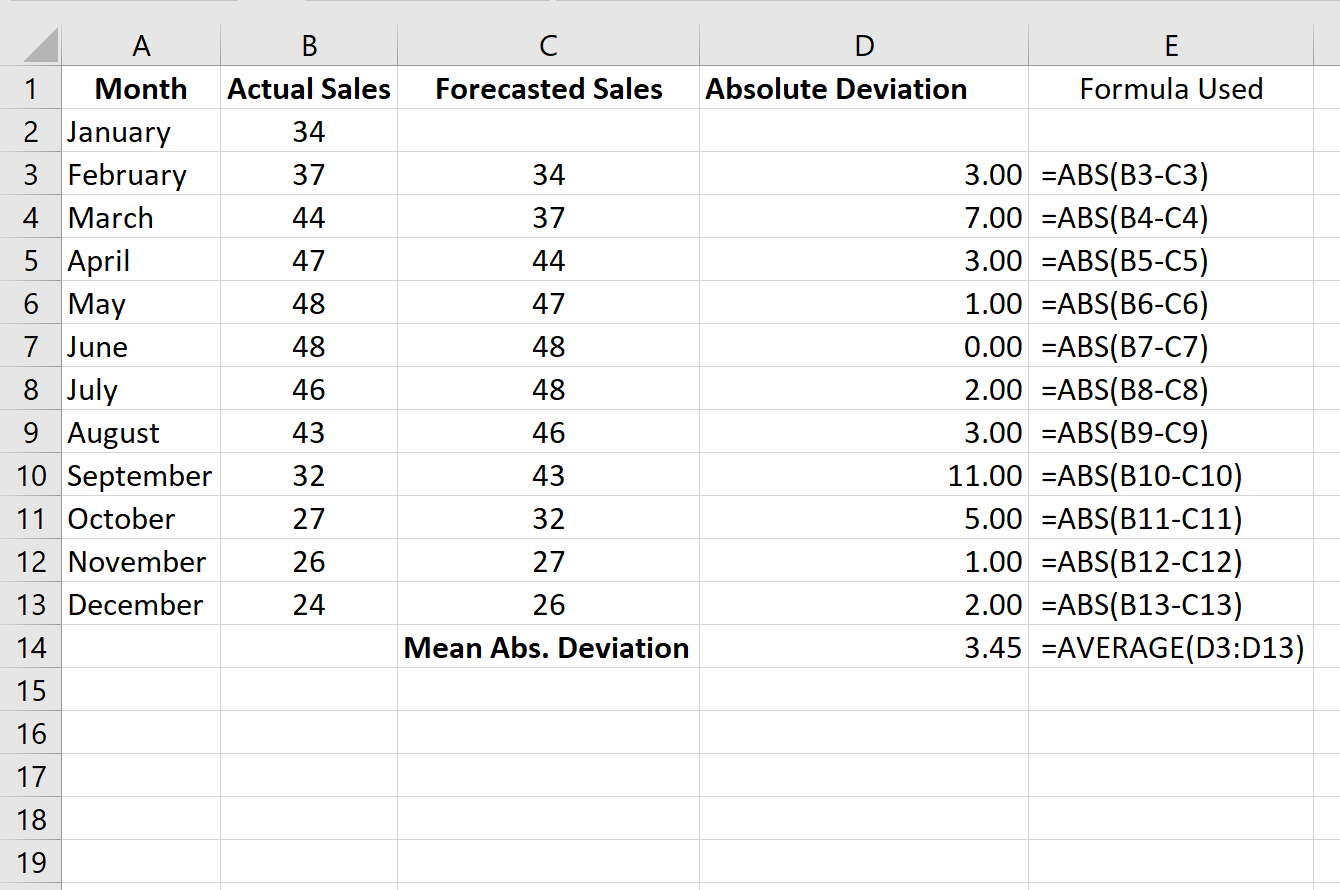
Die mittlere absolute Abweichung beträgt 3,45.
Um zu wissen, ob diese Vorhersage nützlich ist, können wir sie mit anderen Vorhersagemodellen vergleichen und sehen, ob die Genauigkeitsmessungen besser oder schlechter sind.
Das Resampling von Zeitreihendaten bedeutet, die Daten für einen neuen Zeitraum zusammenzufassen oder zu aggregieren.
Wir können die folgende grundlegende Syntax verwenden, um Zeitreihendaten in Python neu abzutasten:
#Finde die …Ein rollierender Median ist der Median einer bestimmten Anzahl früherer Perioden in einer Zeitreihe.
Um den gleitenden Median für eine Spalte in einem Pandas DataFrame zu berechnen, können wir die …