
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
- K: Die Anzahl der Modellparameter …
Eine Kriteriumsvariable ist einfach ein anderer Name für eine abhängige Variable oder eine Antwortvariable. Dies ist die Variable, die in einer statistischen Analyse vorhergesagt wird.
So wie erklärende Variablen unterschiedliche Namen wie Prädiktorvariablen oder unabhängige Variablen haben, hat eine Antwortvariable auch austauschbare Namen wie abhängige Variable oder Kriteriumsvariable.
Die folgenden Szenarien veranschaulichen Beispiele für Kriteriumsvariablen in verschiedenen Einstellungen.
Die einfache lineare Regression ist eine statistische Methode, mit der wir die Beziehung zwischen zwei Variablen, x und y, verstehen. Eine Variable, x, ist als Prädiktorvariable bekannt. Die andere Variable y ist als Kriteriumsvariable oder Antwortvariable bekannt.
In der einfachen linearen Regression finden wir eine „Linie der besten Anpassung“, die die Beziehung zwischen der Prädiktorvariablen und der Kriteriumsvariablen beschreibt.
Beispielsweise können wir ein einfaches lineares Regressionsmodell an einen Datensatz anpassen, indem wir die untersuchten Stunden als Prädiktorvariable und die Testergebnisse als Kriteriumsvariable verwenden. In diesem Fall würden wir einfache lineare Regression, um zu versuchen, den Wert unserer Kriteriumsvariable Testergebnis vorhersagen.
Als weiteres Beispiel können wir ein einfaches lineares Regressionsmodell mithilfe von Gewicht an einen Datensatz anpassen, um den Wert für die Körpergröße für eine Gruppe von Personen vorherzusagen. In diesem Fall ist unsere Kriteriumsvariable die Höhe, da dies der Wert ist, den wir vorhersagen möchten. Wenn wir die Werte für Größe und Gewicht in einem Streudiagramm darstellen würden, wäre das Kriterium Variable Höhe auf der y-Achse:
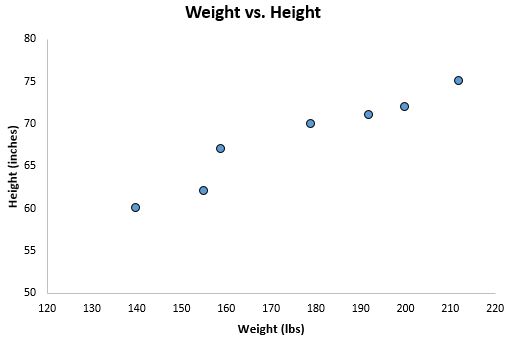
Im Allgemeinen befindet sich die Kriteriumsvariable entlang der y-Achse, wenn wir ein Streudiagramm erstellen, und die Prädiktorvariable befindet sich entlang der x-Achse.
Die multiple lineare Regression ähnelt der einfachen linearen Regression, außer dass wir mehrere Prädiktorvariablen verwenden, um den Wert einer Kriteriumsvariablen vorherzusagen.
Beispielsweise können wir die untersuchten Prädiktorvariablen Stunden und Schlafstunden in der Nacht vor dem Test verwenden, um den Wert des Testergebnisses der Kriteriumsvariablen vorherzusagen. In diesem Fall ist unsere Kriteriumsvariable die Variable, die in dieser Analyse vorhergesagt wird.
Eine ANOVA (Varianzanalyse) ist eine statistische Methode, mit der wir herausfinden, ob es einen statistisch signifikanten Unterschied zwischen den Mittelwerten von drei oder mehr unabhängigen Gruppen gibt.
Zum Beispiel möchten wir vielleicht feststellen, ob drei verschiedene Trainingsprogramme den Gewichtsverlust unterschiedlich beeinflussen. Die Prädiktorvariable, die wir untersuchen, ist ein Übungsprogramm mit drei Ebenen. Die Kriteriumsvariable ist der Gewichtsverlust, gemessen in Pfund. Wir können eine einfaktorielle ANOVA durchführen, um festzustellen, ob es einen statistisch signifikanten Unterschied zwischen dem resultierenden Gewichtsverlust aus den drei Programmen gibt.
In diesem Fall sind wir daran interessiert zu verstehen, ob sich der Wert des Kriteriums variabler Gewichtsverlust zwischen den drei Übungsprogrammen unterscheidet.
Wenn wir stattdessen das Trainingsprogramm und die durchschnittlichen Schlafstunden pro Nacht analysieren würden , würden wir eine Zwei-Wege-ANOVA durchführen, da wir daran interessiert sind, wie zwei Faktoren den Gewichtsverlust beeinflussen. Unsere Kriterienvariable ist jedoch erneut der Gewichtsverlust, da wir daran interessiert sind, wie sich der Wert dieser Variablen für verschiedene Bewegungs- und Schlafniveaus unterscheidet.
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
Die logistische Regression ist eine statistische Methode, die wir verwenden, um ein Regressionsmodell anzupassen, wenn die Antwortvariable binär ist.
Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz …