
Clustering ist eine Technik des maschinellen Lernens, bei der versucht wird, Gruppen oder Cluster von Beobachtungen in einem Datensatz so zu finden, dass die Beobachtungen in jedem Cluster einander sehr …
Clustering ist eine Technik, bei maschinellem Lernen, dass Versuche Cluster zu finden Beobachtungen innerhalb eines Datensatz.
Ziel ist es, Cluster so zu finden, dass die Beobachtungen in jedem Cluster einander sehr ähnlich sind, während Beobachtungen in verschiedenen Clustern sehr unterschiedlich sind.
Clustering ist eine Form des unüberwachtes Lernens, da wir lediglich versuchen, eine Struktur innerhalb eines Datensatzes zu finden, anstatt den Wert einer Antwortvariablen vorherzusagen.
Clustering wird häufig im Marketing eingesetzt, wenn Unternehmen Zugriff auf Informationen haben wie:
- Haushaltseinkommen
- Größe des Haushalts
- Haushaltsvorstand Beruf
- Entfernung vom nächsten Stadtgebiet
Wenn diese Informationen verfügbar sind, kann Clustering verwendet werden, um Haushalte zu identifizieren, die ähnlich sind und möglicherweise eher bestimmte Produkte kaufen oder besser auf eine bestimmte Art von Werbung reagieren.
Eine der häufigsten Formen der Clusterbildung ist das k-Means Clustering.
Was ist K-Means Clustering?
K-Means Clustering ist eine Technik, bei der wir jede Beobachtung in einem Datensatz in einen der K- Cluster einfügen.
Das Endziel besteht darin, K Cluster zu haben, in denen die Beobachtungen innerhalb jedes Clusters einander ziemlich ähnlich sind, während die Beobachtungen in verschiedenen Clustern ziemlich verschieden voneinander sind.
In der Praxis führen wir die folgenden Schritte aus, um ein K-Mittel-Clustering durchzuführen:
1. Wählen Sie einen Wert für K.
- Zunächst müssen wir entscheiden, wie viele Cluster wir in den Daten identifizieren möchten. Oft müssen wir einfach mehrere verschiedene Werte für K testen und die Ergebnisse analysieren, um festzustellen, welche Anzahl von Clustern für ein bestimmtes Problem am sinnvollsten erscheint.
2. Ordnen Sie jede Beobachtung zufällig einem anfänglichen Cluster von 1 bis K zu.
3. Führen Sie die folgenden Schritte aus, bis sich die Clusterzuweisungen nicht mehr ändern.
- Berechnen Sie für jeden der K Cluster den Clusterschwerpunkt . Dies ist einfach der Vektor des p- Merkmalsmittels für die Beobachtungen im _k-_ten Cluster.
- Ordnen Sie jede Beobachtung dem Cluster zu, dessen Schwerpunkt am nächsten liegt. Hier wird der $1 Wert anhand des euklidischen Abstands definiert.
K-Means Clustering in R
Das folgende Tutorial enthält ein schrittweises Beispiel für die Durchführung von k-means-Clustering in R
Schritt 1: Laden Sie die erforderlichen Pakete
Zuerst laden wir zwei Pakete, die mehrere nützliche Funktionen für das k-means-Clustering in R enthalten.
library(factoextra)
library(Cluster)
Schritt 2: Laden und Vorbereiten der Daten
In diesem Beispiel verwenden wir den in R integrierten Datensatz USArrests, der die Anzahl der Verhaftungen pro 100.000 Einwohner in jedem US-Bundesstaat im Jahr 1973 für Mord, $1 und Vergewaltigung sowie den Prozentsatz der Bevölkerung in jedem Bundesstaat, der in städtischen Gebieten lebt, enthält, UrbanPop.
Der folgende Code zeigt, wie Sie Folgendes tun:
- Laden Sie den USArrests- Datensatz
- Entfernen Sie alle Zeilen mit fehlenden Werten
- Skalieren Sie jede Variable im Datensatz auf einen Mittelwert von 0 und eine Standardabweichung von 1
#lade die Daten
df <- USArrests
# Zeilen mit fehlenden Werten entfernen</strong>
df <- na.omit(df)
#skalieren Sie jede Variable auf einen Mittelwert von 0 und einer Standardabweichung von 1</strong>
df <- scale(df)
# Die ersten sechs Zeilen des Datensatzes anzeigen
head(df)
Murder Assault UrbanPop Rape
Alabama 1.24256408 0.7828393 -0.5209066 -0.003416473
Alaska 0.50786248 1.1068225 -1.2117642 2.484202941
Arizona 0.07163341 1.4788032 0.9989801 1.042878388
Arkansas 0.23234938 0.2308680 -1.0735927 -0.184916602
California 0.27826823 1.2628144 1.7589234 2.067820292
Colorado 0.02571456 0.3988593 0.8608085 1.864967207
Schritt 3: Finden Sie die optimale Anzahl von Clustern
Um k-Means Clustering in R durchzuführen, können wir die integrierte Funktion kmeans() verwenden, die die folgende Syntax verwendet:
kmeans(data, centers, nstart)
wo:
- data: Name des Datensatzes.
- centers: Die Anzahl der Cluster, bezeichnet mit k.
- nstart: Die Anzahl der Erstkonfigurationen. Da es möglich ist, dass unterschiedliche anfängliche Startcluster zu unterschiedlichen Ergebnissen führen können, wird empfohlen, mehrere unterschiedliche anfängliche Konfigurationen zu verwenden. Der k-means-Algorithmus findet die Anfangskonfigurationen, die zur kleinsten Variation innerhalb des Clusters führen.
Da wir vorher nicht wissen, wie viele Cluster optimal sind, erstellen wir zwei verschiedene Diagramme, die uns bei der Entscheidung helfen können:
1. Anzahl der Cluster im Vergleich zur Summe innerhalb der Quadratsumme
Zuerst verwenden wir die Funktion fviz_nbclust(), um ein Diagramm der Anzahl der Cluster gegen die Summe innerhalb der Summe der Quadrate zu erstellen:
fviz_nbclust(df, kmeans, method = "wss")
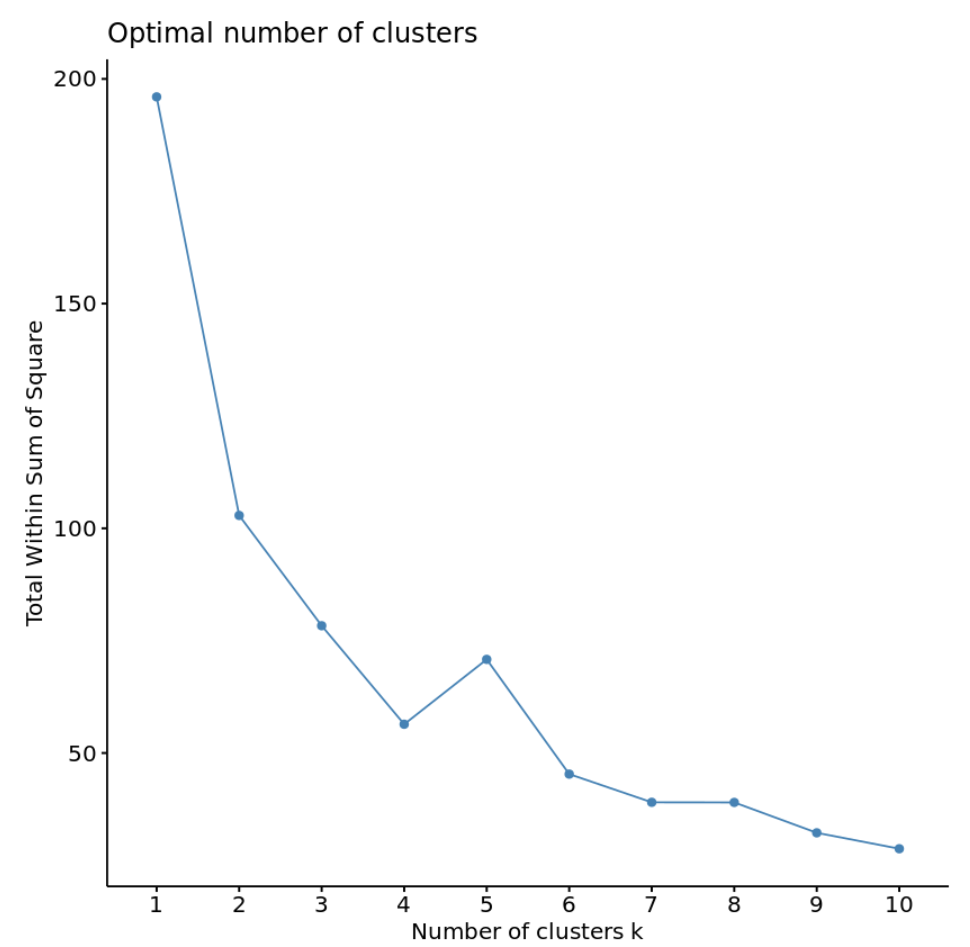
Wenn wir diese Art von Plot erstellen, suchen wir normalerweise nach einem „Ellbogen“, bei dem sich die Summe der Quadrate zu „biegen“ oder zu glätten beginnt. Dies ist normalerweise die optimale Anzahl von Clustern.
Für dieses Diagramm scheint es bei k = 4 Clustern einen kleinen Ellbogen oder eine „Biegung“ zu geben.
2. Anzahl der Cluster vs. Lückenstatistik
Eine andere Möglichkeit, die optimale Anzahl von Clustern zu bestimmen, besteht darin, eine als Gap-Statistik bekannte Metrik zu verwenden, die die gesamte Variation innerhalb des Clusters für verschiedene Werte von k mit ihren erwarteten Werten für eine Verteilung ohne Clustering vergleicht.
Wir können die Lückenstatistik für jede Anzahl von Clustern mithilfe der Funktion clusGap() aus dem Clusterpaket zusammen mit einer Darstellung der Clusterstatistik gegen die Lückenstatistik mithilfe der Funktion fviz_gap_stat() berechnen:
#Berechnen Sie die Lückenstatistik basierend auf der Anzahl der Cluster
gap_stat <- clusGap(df,
FUN = kmeans,
nstart = 25,
K.max = 10,
B = 50)
#Plotten der Anzahl der Cluster vs. Lückenstatistik
fviz_gap_stat(gap_stat)
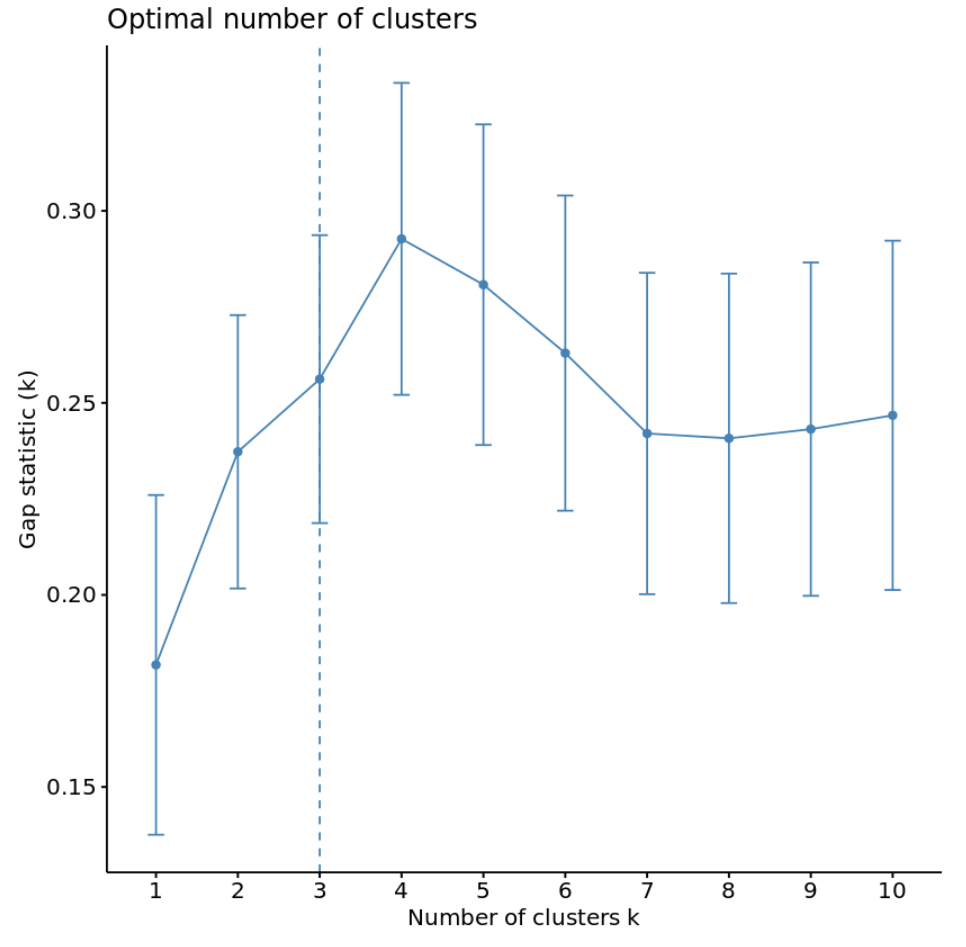
Aus dem Diagramm können wir ersehen, dass die Lückenstatistik bei k = 4 Clustern am höchsten ist, was der zuvor verwendeten Ellbogenmethode entspricht.
Schritt 4: Führen Sie K-Means Clustering mit optimalem K durch
Zuletzt können wir k-means Clustering für den Datensatz durchführen, indem wir den optimalen Wert für k von 4 verwenden:
#Machen Sie dieses Beispiel reproduzierbar
set.seed(1)
#Durchführen von k-Means Clustering mit k = 4 Clustern
km <- kmeans(df, centers = 4, nstart = 25)
#Ergebnisse anzeigen
km
K-means clustering with 4 clusters of sizes 16, 13, 13, 8
Cluster means:
Murder Assault UrbanPop Rape
1 -0.4894375 -0.3826001 0.5758298 -0.26165379
2 -0.9615407 -1.1066010 -0.9301069 -0.96676331
3 0.6950701 1.0394414 0.7226370 1.27693964
4 1.4118898 0.8743346 -0.8145211 0.01927104
Clustering vector:
Alabama Alaska Arizona Arkansas California Colorado
4 3 3 4 3 3
Connecticut Delaware Florida Georgia Hawaii Idaho
1 1 3 4 1 2
Illinois Indiana Iowa Kansas Kentucky Louisiana
3 1 2 1 2 4
Maine Maryland Massachusetts Michigan Minnesota Mississippi
2 3 1 3 2 4
Missouri Montana Nebraska Nevada New Hampshire New Jersey
3 2 2 3 2 1
New Mexico New York North Carolina North Dakota Ohio Oklahoma
3 3 4 2 1 1
Oregon Pennsylvania Rhode Island South Carolina South Dakota Tennessee
1 1 1 4 2 4
Texas Utah Vermont Virginia Washington West Virginia
3 1 2 1 1 2
Wisconsin Wyoming
2 1
Within cluster sum of squares by cluster:
[1] 16.212213 11.952463 19.922437 8.316061
(between_SS / total_SS = 71.2 %)
Available components:
[1] "cluster" "centers" "totss" "withinss" "tot.withinss" "betweenss"
[7] "size" "iter" "ifault"
Aus den Ergebnissen können wir Folgendes ersehen:
- Dem ersten Cluster wurden 16 Zustände zugewiesen
- Dem zweiten Cluster wurden 13 Zustände zugewiesen
- Dem dritten Cluster wurden 13 Zustände zugeordnet
- Dem vierten Cluster wurden 8 Zustände zugewiesen
Mit der Funktion fivz_cluster() können wir die Cluster in einem Streudiagramm visualisieren, in dem die ersten beiden Hauptkomponenten auf den Achsen angezeigt werden:
#Plotten der Ergebnisse des endgültigen k-means-Modells
fviz_cluster(km, data = df)

Wir können auch die Funktion aggreg() verwenden, um den Mittelwert der Variablen in jedem Cluster zu ermitteln:
#Finen des Mittelwerts für jeden Cluster
aggregate(USArrests, by=list(cluster=km$cluster), mean)
cluster Murder Assault UrbanPop Rape
1 3.60000 78.53846 52.07692 12.17692
2 10.81538 257.38462 76.00000 33.19231
3 5.65625 138.87500 73.87500 18.78125
4 13.93750 243.62500 53.75000 21.41250
Wir interpretieren diese Ausgabe wie folgt:
- Die durchschnittliche Anzahl der Morde pro 100.000 Bürger unter den Staaten in Cluster 1 beträgt 3,6.
- Die durchschnittliche Anzahl der Übergriffe pro 100.000 Bürger unter den Staaten in Cluster 1 beträgt 78,5.
- Der durchschnittliche Prozentsatz der in einem städtischen Gebiet lebenden Einwohner unter den Bundesstaaten in Cluster 1 beträgt 52,1%.
- Die durchschnittliche Anzahl von Vergewaltigungen pro 100.000 Bürger unter den Staaten in Cluster 1 beträgt 12,2.
Und so weiter.
Wir können auch die Clusterzuweisungen jedes Status wieder an den ursprünglichen Datensatz anhängen:
#Clusterzuordnung zu Originaldaten hinzufügen
final_data <- cbind(USArrests, cluster = km$cluster)
#Enddaten anzeigen
head(final_data)
Murder Assault UrbanPop Rape cluster
Alabama 13.2 236 58 21.2 4
Alaska 10.0 263 48 44.5 2
Arizona 8.1 294 80 31.0 2
Arkansas 8.8 190 50 19.5 4
California 9.0 276 91 40.6 2
Colorado 7.9 204 78 38.7 2
Vor- und Nachteile von K-Means Clustering
K-means Clustering bietet folgende Vorteile:
- Es ist ein schneller Algorithmus.
- Es kann gut mit großen Datenmengen umgehen.
Es bringt jedoch die folgenden möglichen Nachteile mit sich:
- Wir müssen die Anzahl der Cluster angeben, bevor wir den Algorithmus ausführen.
- Es ist empfindlich gegenüber Ausreißern.
Zwei Alternativen zum k-means-Clustering sind das k-medoids-Clustering und das hierarchische Clustering.
Den vollständigen R-Code, der in diesem Beispiel verwendet wird, finden Sie hier.
Das könnte Sie auch interessieren:
Hierarchisches Clustering in R: Schritt-für-Schritt-Beispiel
K-Medoid-Clustering in R: Schritt-für-Schritt-Beispiel
Clustering ist eine Technik des maschinellen Lernens, bei der versucht wird, Gruppen oder Cluster von Beobachtungen innerhalb eines Datensatzes zu finden.
Ziel ist es, Cluster so zu finden, dass die …