
Clustering ist eine Technik des maschinellen Lernens, bei der versucht wird, Gruppen oder Cluster von Beobachtungen innerhalb eines Datensatzes zu finden.
Ziel ist es, Cluster so zu finden, dass die …
Clustering ist eine Technik des maschinellen Lernens, bei der versucht wird, Gruppen oder Cluster von Beobachtungen in einem Datensatz so zu finden, dass die Beobachtungen in jedem Cluster einander sehr ähnlich sind, während Beobachtungen in verschiedenen Clustern sich stark voneinander unterscheiden.
Clustering ist eine Form des unüberwachten Lernens, da wir lediglich versuchen, eine Struktur innerhalb eines Datensatzes zu finden, anstatt den Wert einer Antwortvariablen vorherzusagen.
Clustering wird häufig im Marketing eingesetzt, wenn Unternehmen Zugriff auf Informationen haben wie:
Wenn diese Informationen verfügbar sind, kann Clustering verwendet werden, um Haushalte zu identifizieren, die ähnlich sind und möglicherweise eher bestimmte Produkte kaufen oder besser auf eine bestimmte Art von Werbung reagieren.
Eine der häufigsten Formen der Clusterbildung ist die k-Means-Clustering. Leider müssen wir bei dieser Methode die Anzahl der Cluster K vorab festlegen.
Eine Alternative zu dieser Methode ist das hierarchische Clustering, bei dem die Anzahl der zu verwendenden Cluster nicht vorab festgelegt werden muss. Außerdem kann eine baumbasierte Darstellung der als Dendrogramm bekannten Beobachtungen erstellt werden.
Ähnlich wie bei der k-Mittelwert-Clusterbildung besteht das Ziel der hierarchischen Clusterbildung darin, Beobachtungscluster zu erzeugen, die einander sehr ähnlich sind, während sich die Beobachtungen in verschiedenen Clustern stark voneinander unterscheiden.
In der Praxis führen wir die folgenden Schritte aus, um hierarchisches Clustering durchzuführen:
1. Berechnen Sie die paarweise Unähnlichkeit zwischen jeder Beobachtung im Datensatz.
2. Verschmelzen Sie Beobachtungen zu Clustern.
Um festzustellen, wie nahe zwei Cluster beieinander liegen, können wir verschiedene Methoden verwenden, darunter:
Abhängig von der Struktur des Datensatzes kann eine dieser Methoden dazu neigen, bessere (d.h. kompaktere) Cluster zu erzeugen als die anderen Methoden.
Das folgende Tutorial enthält ein schrittweises Beispiel für die Durchführung eines hierarchischen Clusters in R
Zuerst laden wir zwei Pakete, die mehrere nützliche Funktionen für das hierarchische Clustering in R enthalten.
library(factoextra)
library(cluster)
In diesem Beispiel verwenden wir den in R integrierten Datensatz USArrests, der die Anzahl der Festnahmen pro 100.000 Einwohner in jedem US-Bundesstaat im Jahr 1973 für Mord, integrierten und Vergewaltigung sowie den Prozentsatz der Bevölkerung in jedem Bundesstaat, der in städtischen Gebieten lebt, enthält, UrbanPop.
Der folgende Code zeigt, wie Sie Folgendes tun:
#lade Daten
df <- USArest
#Zeilen mit fehlenden Werten entfernen
df <- na.omit(df)
#skalieren Sie jede Variable auf einen Mittelwert von 0 und eine Standardabweichung von 1
df <- scale(df)
# Die ersten sechs Zeilen des Datensatzes anzeigen
head (df)
Murder Assault UrbanPop Rape
Alabama 1.24256408 0.7828393 -0.5209066 -0.003416473
Alaska 0.50786248 1.1068225 -1.2117642 2.484202941
Arizona 0.07163341 1.4788032 0.9989801 1.042878388
Arkansas 0.23234938 0.2308680 -1.0735927 -0.184916602
California 0.27826823 1.2628144 1.7589234 2.067820292
Colorado 0.02571456 0.3988593 0.8608085 1.864967207
Um hierarchisches Clustering in R durchzuführen, können wir die Funktion agnes() aus dem Clusterpaket verwenden , die die folgende Syntax verwendet:
agnes(data, method)
wo:
Da wir vorher nicht wissen, welche Methode die besten Cluster erzeugt, können wir eine kurze Funktion schreiben, um hierarchisches Clustering mit verschiedenen Methoden durchzuführen.
Beachten Sie, dass diese Funktion den Agglomerationskoeffizienten jeder Methode berechnet. Diese Metrik misst die Stärke der Cluster. Je näher dieser Wert an 1 liegt, desto stärker sind die Cluster.
#Verknüpfungsmethoden definieren
m <- c( "average", "single", "complete", "ward")
names(m) <- c( "average", "single", "complete", "ward")
# Funktion zur Berechnung des Agglomerationskoeffizienten
ac <- function(x) {
agnes(df, method = x)$ac
}
# Berechnen Sie den Agglomerationskoeffizienten für jede Clustering-Verknüpfungsmethode
sapply(m, ac)
average single complete ward
0.7379371 0.6276128 0.8531583 0.9346210
Wir können sehen, dass die Minimalvarianzmethode von Ward den höchsten Agglomerationskoeffizienten erzeugt, daher verwenden wir diesen als Methode für unsere endgültige hierarchische Clusterbildung:
#Führen Sie hierarchisches Clustering mit der minimalen Varianz von Ward durch
clust <- agnes(df, method = "ward")
#Dendrogramm produzieren
pltree (clust, cex = 0,6, hang = -1, main = "Dendrogram")
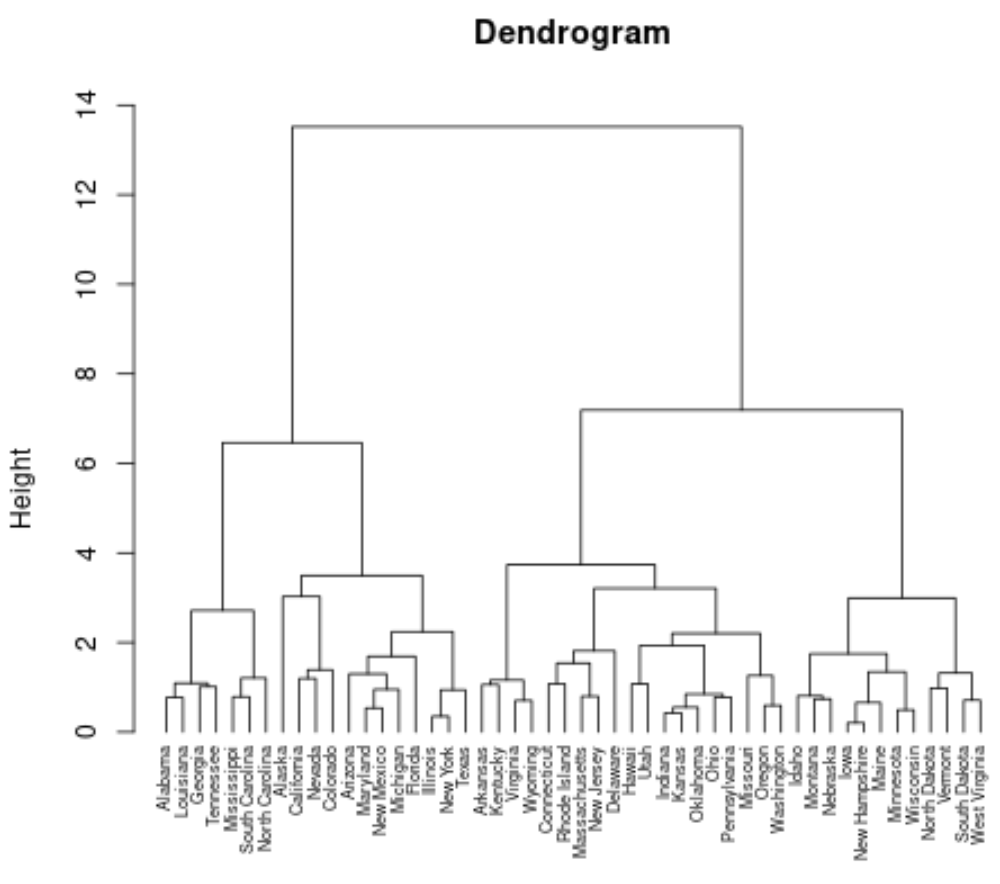
Jedes Blatt am unteren Rand des Dendrogramms repräsentiert eine Beobachtung im Originaldatensatz. Wenn wir das Dendrogramm von unten nach oben bewegen, werden einander ähnliche Beobachtungen zu einem Zweig verschmolzen.
Um zu bestimmen, in wie vielen Clustern die Beobachtungen gruppiert werden sollen, können wir eine als Gap-Statistik bekannte Metrik verwenden, die die gesamte Variation innerhalb des Clusters für verschiedene Werte von k mit ihren erwarteten Werten für eine Verteilung ohne Clustering vergleicht.
Wir können die Lückenstatistik für jede Anzahl von Clustern mit der Funktion clusGap() aus dem Clusterpaket zusammen mit einem Diagramm der Cluster gegen die Lückenstatistik mit der Funktion fviz_gap_stat() berechnen:
#Berechnung der Lückenstatistik für jede Anzahl von Clustern (bis zu 10 Cluster)
gap_stat <- clusGap(df, FUN = hcut, nstart = 25, K.max = 10, B = 50)
#Protokoll von Clustern gegen Lückenstatistik erstellen
fviz_gap_stat(gap_stat)
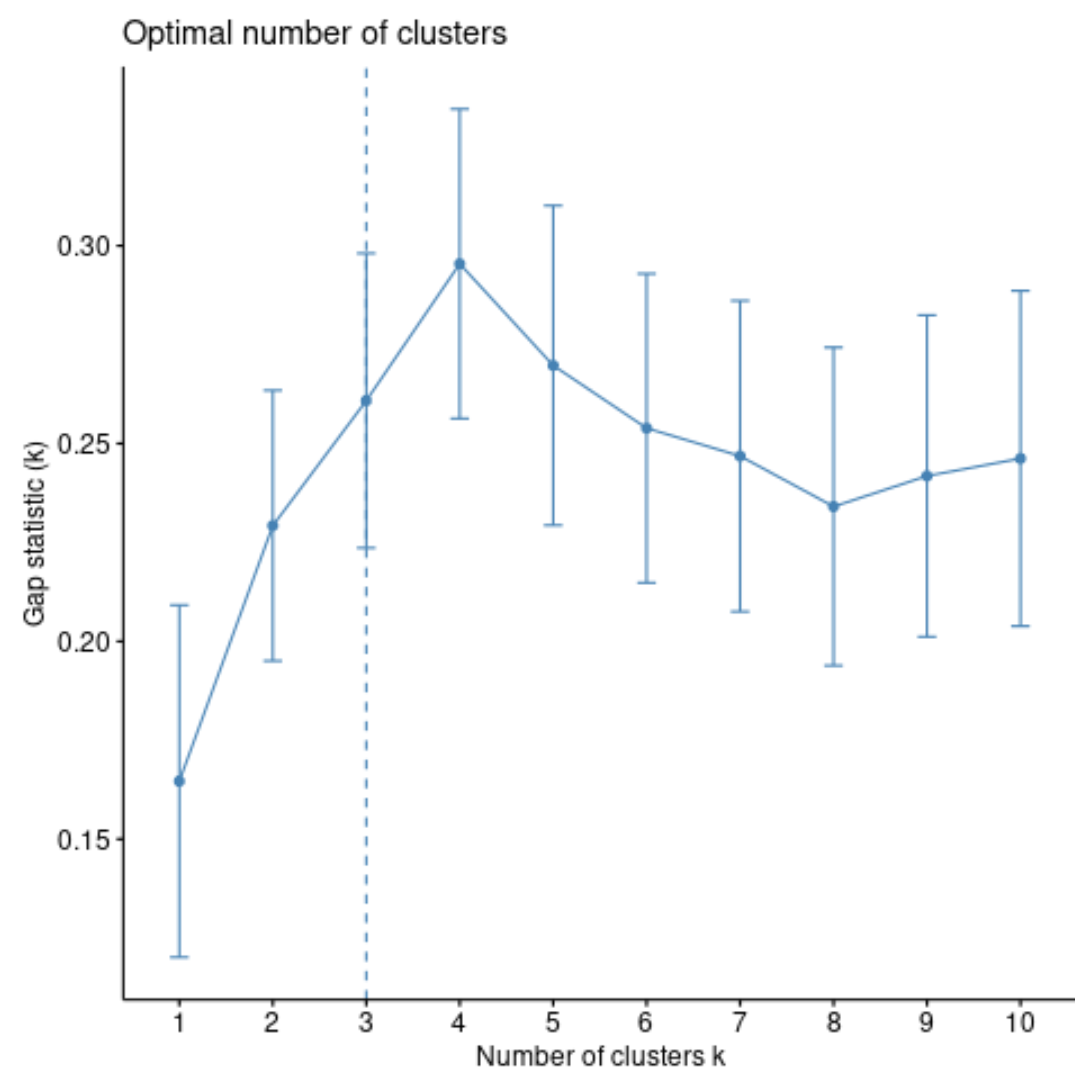
Aus dem Diagramm können wir sehen, dass die Lückenstatistik bei k = 4 Clustern am höchsten ist. Daher werden wir unsere Beobachtungen in 4 verschiedene Cluster gruppieren.
Um jeder Beobachtung in unserem Datensatz tatsächlich Cluster-Labels hinzuzufügen, können wir das cutd()-Methode verwenden, um das Dendrogramm in 4 Cluster zu schneiden:
#Entfernungsmatrix berechnen
d <- dist(df, method = "euklidisch")
#hierarchisches Clustering mit der Ward-Methode durchführen
final_clust <- hclust(d, method = "ward.D2")
#Schneiden Sie das Dendrogramm in 4 Cluster
groups <- cutree(final_clust, k = 4)
#Anzahl der Beobachtungen in jedem Cluster finden
table(groups)
1 2 3 4
7 12 19 12
Wir können dann die Cluster-Beschriftungen jedes Status wieder an den ursprünglichen Datensatz anhängen:
#Clusterbezeichnungen an Originaldaten anhängen
final_data <- cbind(USArrests, cluster = groups)
#Die ersten sechs Zeilen der endgültigen Daten anzeigen
head(final_data)
Murder Assault UrbanPop Rape cluster
Alabama 13.2 236 58 21.2 1
Alaska 10.0 263 48 44.5 2
Arizona 8.1 294 80 31.0 2
Arkansas 8.8 190 50 19.5 3
California 9.0 276 91 40.6 2
Colorado 7.9 204 78 38.7 2
Zuletzt können wir die Funktion aggregate() verwenden, um den Mittelwert der Variablen in jedem Cluster zu ermitteln:
#Mittelwerte für jeden Cluster finden
aggregate(final_data, by = list(cluster=final_data$cluster), mean)
cluster Murder Assault UrbanPop Rape cluster
1 1 14.671429 251.2857 54.28571 21.68571 1
2 2 10.966667 264.0000 76.50000 33.60833 2
3 3 6.210526 142.0526 71.26316 19.18421 3
4 4 3.091667 76.0000 52.08333 11.83333 4
Wir interpretieren diese Ausgabe wie folgt:
Den vollständigen R-Code, der in diesem Beispiel verwendet wird, finden Sie hier.
Clustering ist eine Technik des maschinellen Lernens, bei der versucht wird, Gruppen oder Cluster von Beobachtungen innerhalb eines Datensatzes zu finden.
Ziel ist es, Cluster so zu finden, dass die …
Die Hauptkomponentenanalyse, oft als PCA (engl. Principal Component Analysis) abgekürzt, ist eine unüberwachte maschinelle Lerntechnik, mit der versucht wird, Hauptkomponenten - lineare Kombinationen der ursprünglichen Prädiktoren - zu finden, die einen großen …