
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
- K: Die Anzahl der Modellparameter …
Hierarchische Regression ist eine Technik, mit der wir verschiedene lineare Modelle vergleichen können.
Die Grundidee ist, dass wir zuerst ein lineares Regressionsmodell mit nur einer erklärenden Variablen anpassen. Dann passen wir ein anderes Regressionsmodell unter Verwendung einer zusätzlichen erklärenden Variablen an. Wenn das R-Quadrat (der Anteil der Varianz in der Antwortvariablen, der durch die erklärenden Variablen erklärt werden kann) im zweiten Modell signifikant höher ist als das R-Quadrat im vorherigen Modell, bedeutet dies, dass das zweite Modell besser ist.
Anschließend wiederholen wir den Vorgang des Anpassen zusätzlicher Regressionsmodelle mit erklärenderen Variablen und prüfen, ob die neueren Modelle eine Verbesserung gegenüber den vorherigen Modellen bieten.
Dieses Tutorial enthält ein Beispiel für die Durchführung einer hierarchischen Regression in Stata.
Wir werden ein integriertes Dataset namens auto verwenden, um zu veranschaulichen, wie eine hierarchische Regression in Stata durchgeführt wird. Laden Sie zunächst den Datensatz, indem Sie Folgendes in das Befehlsfeld eingeben:
sysuse auto
Mit dem folgenden Befehl können wir eine schnelle Zusammenfassung der Daten erhalten:
summarize
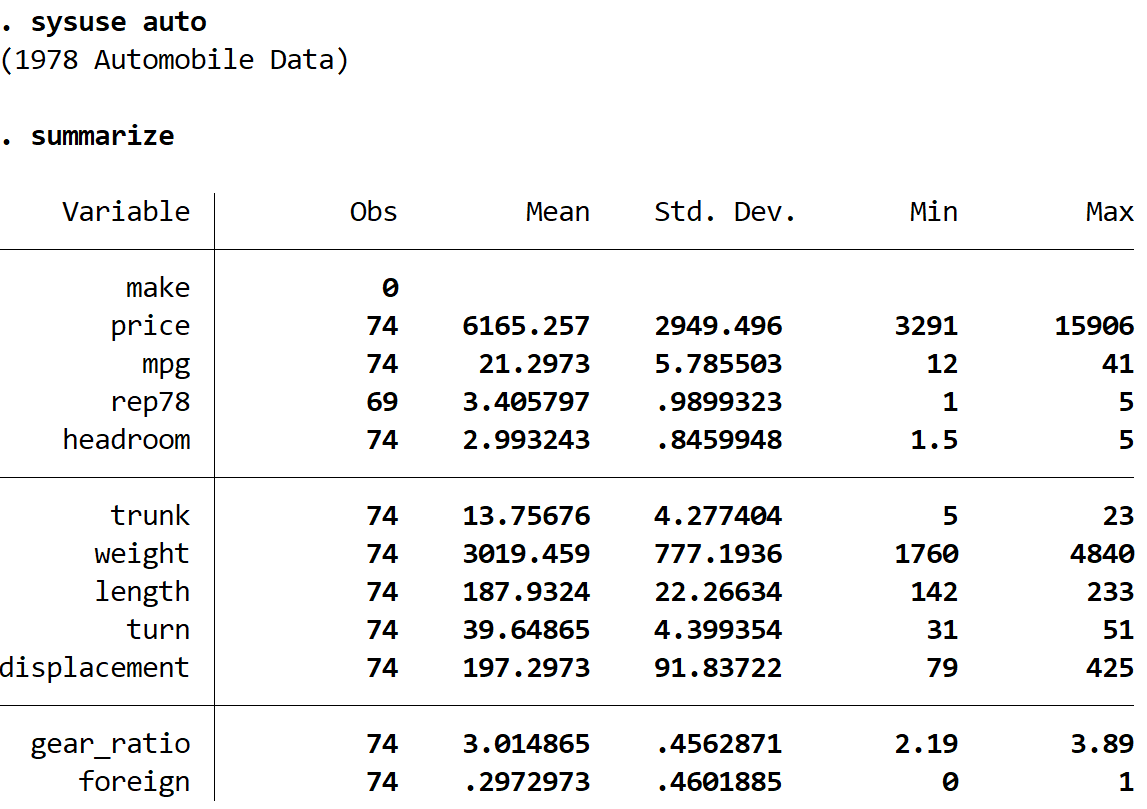
Wir können sehen, dass der Datensatz Informationen zu 12 verschiedenen Variablen für insgesamt 74 Autos enthält.
Wir werden die folgenden drei linearen Regressionsmodelle anpassen und die hierarchische Regression verwenden, um festzustellen, ob jedes nachfolgende Modell eine signifikante Verbesserung gegenüber dem vorherigen Modell bietet oder nicht:
Modell 1: price = intercept + mpg
Modell 2: price = intercept + mpg + weight
Modell 3: price = intercept + mpg + weight + gear ratio
Um eine hierarchische Regression in Stata durchzuführen, müssen wir zuerst das hireg-Paket installieren. Geben Sie dazu Folgendes in das Befehlsfeld ein:
findit hireg
Klicken Sie im angezeigten Fenster auf hireg from http://fmwww.bc.edu/RePEc/bocode/h
Klicken Sie im nächsten Fenster auf den Link „click here to install“.

Das Paket wird in wenigen Sekunden installiert. Als nächstes verwenden wir den folgenden Befehl, um eine hierarchische Regression durchzuführen:
hireg price (mpg) (weight) (gear_ratio)
Dies fordert Stata auf, Folgendes zu tun:
Hier ist die Ausgabe des ersten Modells:
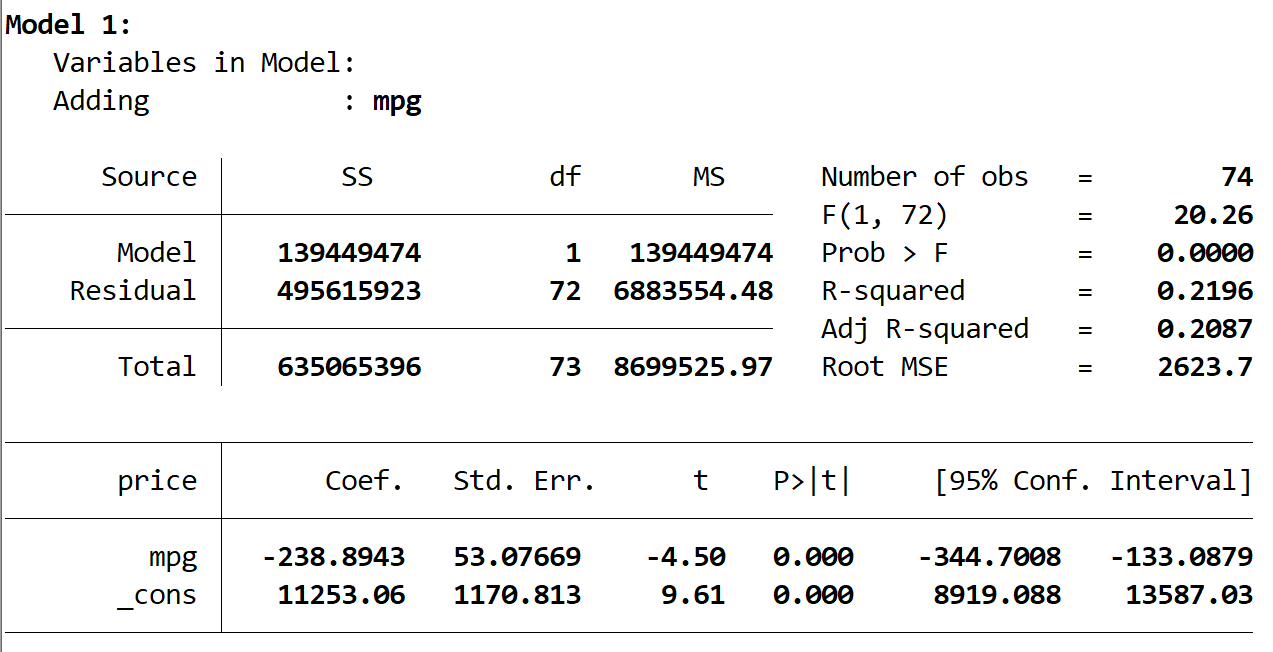
Wir sehen, dass das R-Quadrat des Modells 0,2196 beträgt und der Gesamt-p-Wert (Prob> F) für das Modell 0,0000 beträgt, was bei α = 0,05 statistisch signifikant ist.
Als nächstes sehen wir die Ausgabe des zweiten Modells:
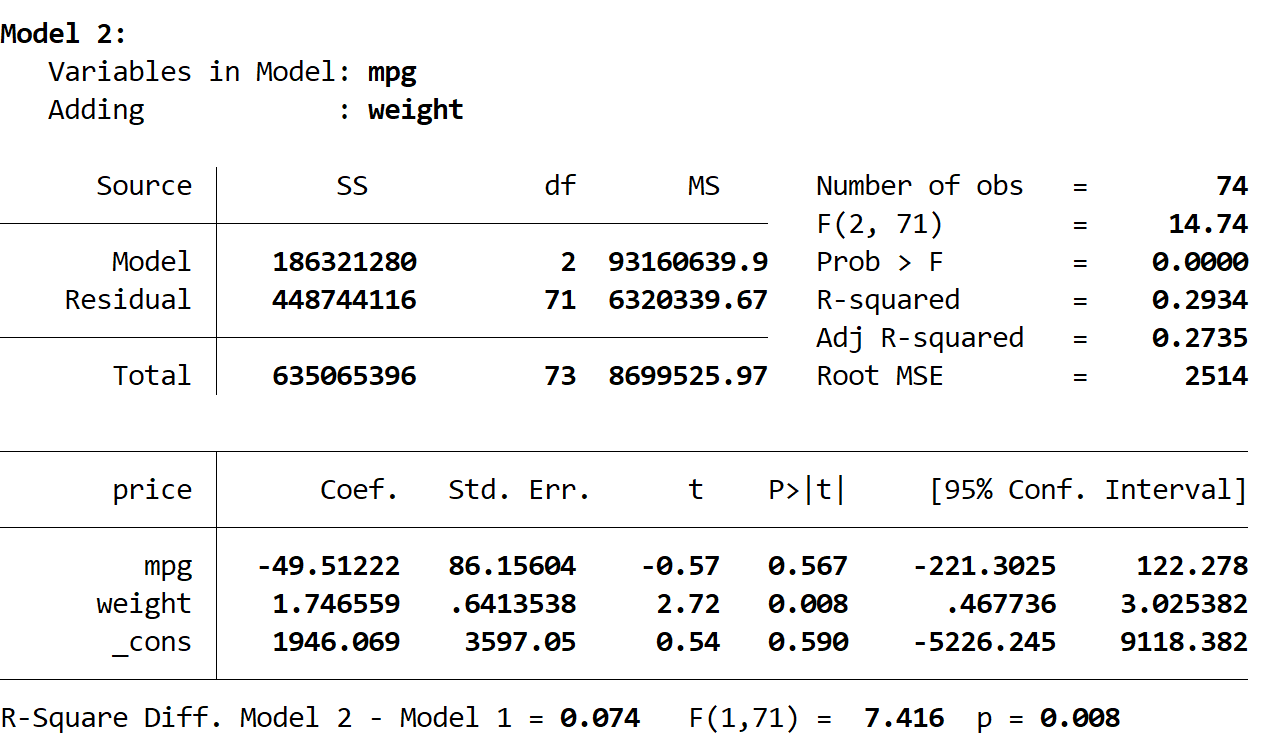
Das R-Quadrat dieses Modells beträgt 0,2934 und ist damit größer als das erste Modell. Um festzustellen, ob dieser Unterschied statistisch signifikant ist, führte Stata einen F-Test durch, der die folgenden Zahlen am unteren Rand der Ausgabe ergab:
Da der p-Wert weniger als 0,05 beträgt, schließen wir, dass das zweite Modell im Vergleich zum ersten Modell statistisch signifikant verbessert ist.
Zuletzt können wir die Ausgabe des dritten Modells sehen:
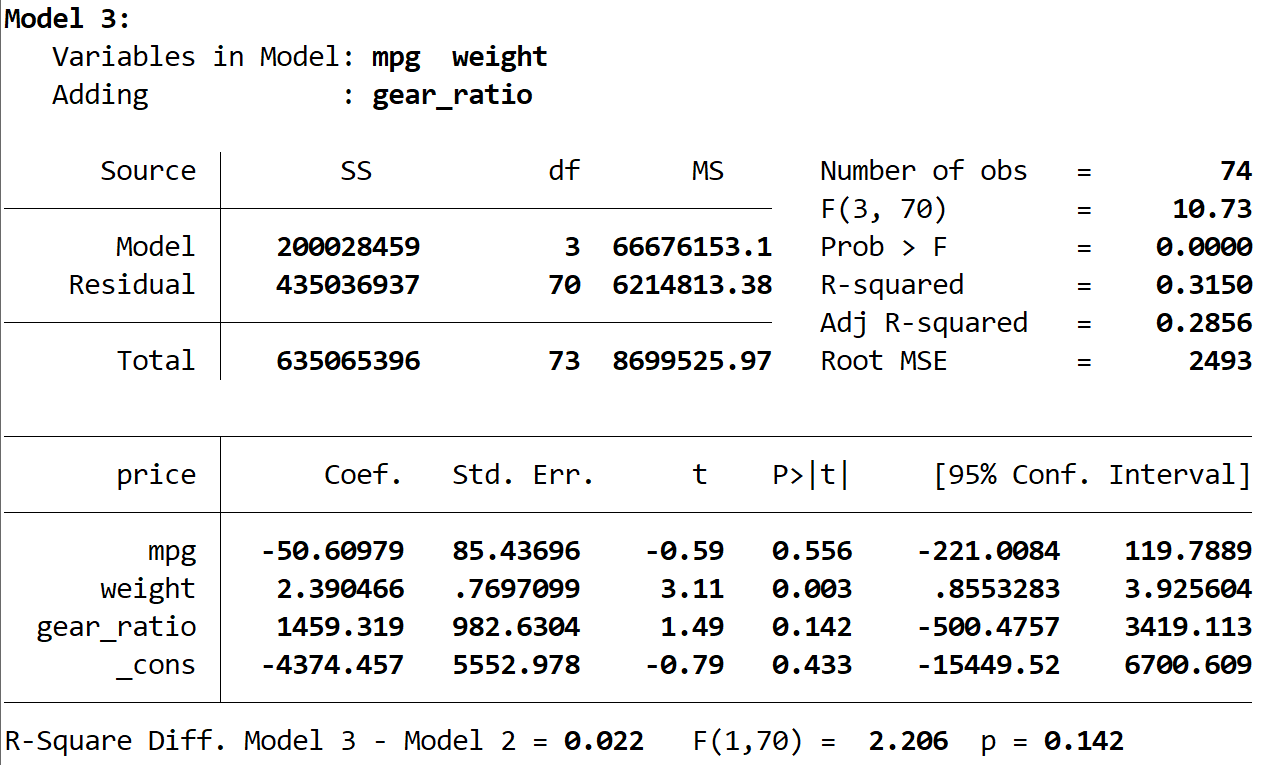
Das R-Quadrat dieses Modells beträgt 0,3150, was größer als das zweite Modell ist. Um festzustellen, ob dieser Unterschied statistisch signifikant ist, führte Stata einen F-Test durch, der die folgenden Zahlen am unteren Rand der Ausgabe ergab:
Da der p-Wert nicht weniger als 0,05 beträgt, gibt es keine ausreichenden Beweise dafür, dass das dritte Modell eine Verbesserung gegenüber dem zweiten Modell bietet.
Ganz am Ende der Ausgabe sehen wir, dass Stata eine Zusammenfassung der Ergebnisse liefert:

In diesem speziellen Beispiel würden wir den Schluss ziehen, dass Modell 2 eine signifikante Verbesserung gegenüber Modell 1 bietet, Modell 3 jedoch keine signifikante Verbesserung gegenüber Modell 2.
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
Die logistische Regression ist eine statistische Methode, die wir verwenden, um ein Regressionsmodell anzupassen, wenn die Antwortvariable binär ist.
Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz …