
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
- K: Die Anzahl der Modellparameter …
Der Cook-Abstand wird verwendet, um einflussreiche Beobachtungen in einem Regressionsmodell zu identifizieren.
Die Formel für den Cook-Abstand lautet:
D i = (r i 2 / p * MSE) * (h ii / (1-h ii ) 2 )
wo:
Im Wesentlichen misst den Cook-Abstand, um wie viel sich alle angepassten Werte im Modell ändern, wenn die i-te Beobachtung gelöscht wird.
Je größer der Wert für den Cook-Abstand ist, desto einflussreicher ist eine bestimmte Beobachtung.
Eine allgemeine Faustregel lautet, dass jede Beobachtung mit einem Cook-Abstand von mehr als 4 / n (wobei n = Gesamtbeobachtungen) als sehr einflussreich angesehen wird.
Dieses Tutorial enthält ein schrittweises Beispiel für die Berechnung des Cook-Abstands für ein bestimmtes Regressionsmodell in Python.
Zuerst erstellen wir einen kleinen Datensatz, mit dem Sie in Python arbeiten können:
import pandas as pd
# Datensatz erstellen
df = pd.DataFrame({'x': [8, 12, 12, 13, 14, 16, 17, 22, 24, 26, 29, 30],
'y': [41, 42, 39, 37, 35, 39, 45, 46, 39, 49, 55, 57]})
Als nächstes passen wir ein einfaches lineares Regressionsmodell an:
import statsmodels.api as sm
# Antwortvariable definieren
y = df['y']
# erklärende Variable definieren
x = df['x']
# Konstante zu Prädiktorvariablen hinzufügen
x = sm.add_constant(x)
# lineares Regressionsmodell anpassen
model = sm.OLS(y, x).fit()
Als nächstes berechnen wir den Cook-Abstand für jede Beobachtung im Modell:
#suppress wissenschaftliche Notation
import numpy as np
np.set_printoptions(suppress=True)
# Instanz des Einflusses erstellen
influence = model.get_influence()
# Erhalten Sie für jede Beobachtung den Abstand von Cook
cooks = influence.cooks_distance
# Cook-Abstand anzeigen
print(cooks)
(array([0.368, 0.061, 0.001, 0.028, 0.105, 0.022, 0.017, 0. , 0.343,
0. , 0.15 , 0.349]),
array([0.701, 0.941, 0.999, 0.973, 0.901, 0.979, 0.983, 1. , 0.718,
1. , 0.863, 0.713]))
Standardmäßig zeigt die Funktion cooks_distance() für jede Beobachtung ein Array von Werten für den Cook-Abstand an, gefolgt von einem Array entsprechender p-Werte.
Beispielsweise:
Und so weiter.
Zuletzt können wir ein Streudiagramm erstellen, um die Werte für die Prädiktorvariable gegenüber dem Cook-Abstand für jede Beobachtung zu visualisieren:
import matplotlib.pyplot as plt
plt.scatter(df.x, cooks[0])
plt.xlabel('x')
plt.ylabel('Cooks Distance')
plt.show()
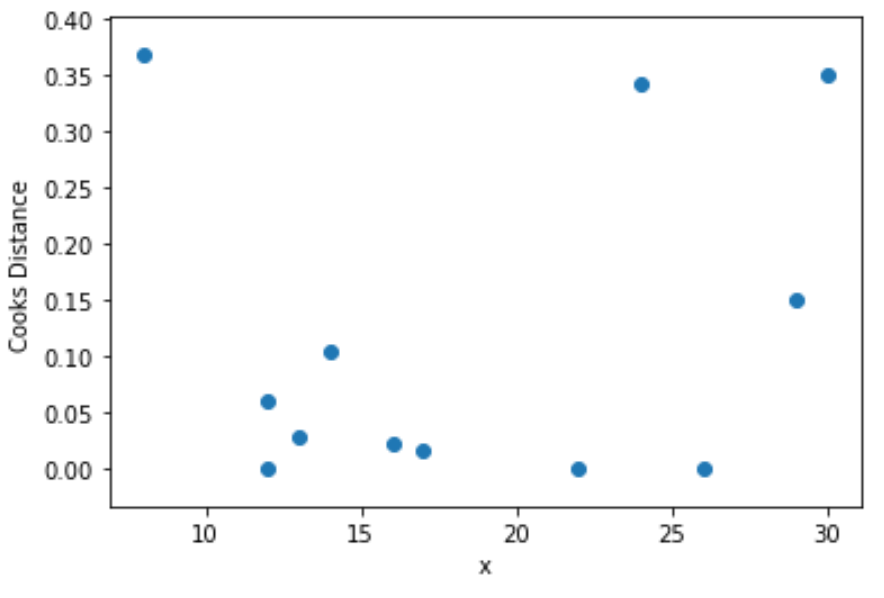
Es ist wichtig zu beachten, dass der Cook-Abstand verwendet werden sollte, um potenziell einflussreiche Beobachtungen zu identifizieren. Nur weil eine Beobachtung einflussreich ist, bedeutet dies nicht unbedingt, dass sie aus dem Datensatz gelöscht werden sollte.
Zunächst sollten Sie sicherstellen, dass die Beobachtung nicht auf einen Dateneingabefehler oder ein anderes ungewöhnliches Ereignis zurückzuführen ist. Wenn sich herausstellt, dass es sich um einen legitimen Wert handelt, können Sie entscheiden, ob es angemessen ist, ihn zu löschen, zu belassen oder einfach durch einen alternativen Wert wie den Median zu ersetzen.
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
Die logistische Regression ist eine statistische Methode, die wir verwenden, um ein Regressionsmodell anzupassen, wenn die Antwortvariable binär ist.
Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz …