
Das Latin Hypercube Stichprobenverfahren ist eine Methode, die zur Stichprobenziehung von Zufallszahlen verwendet werden kann, bei der die Stichproben gleichmäßig über einen Stichprobenraum verteilt sind.
Es wird häufig verwendet, um …
Wann immer Sie einen statistischen Test durchführen, ist es möglich, dass Sie rein zufällig einen p-Wert von weniger als 0,05 erhalten, selbst wenn Ihre Nullhypothese wahr ist.
Angenommen, Sie möchten wissen, ob eine bestimmte Pflanze eine mittlere Höhe von mehr als 10 Zoll hat. Ihre Null- und Alternativhypothesen für den Test wären:
H0: μ = 10 Zoll
HA: μ > 10 Zoll
Um diese Hypothese zu testen, können Sie eine zufällige Stichprobe von 20 Pflanzen zur Messung entnehmen. Selbst wenn die wahre mittlere Höhe dieser Pflanzenart 10 Zoll beträgt, ist es möglich, dass Sie eine Stichprobe von 20 Pflanzen ausgewählt haben, die ungewöhnlich groß waren, was dazu führt, dass Sie die Nullhypothese ablehnen.
Obwohl die Nullhypothese wahr war (die mittlere Höhe dieser Pflanze betrug tatsächlich 10 Zoll), haben Sie sie abgelehnt. In der Statistik nennen wir dies eine „falsche Entdeckung“. Sie haben behauptet, eine Entdeckung gemacht zu haben – ein „signifikantes Ergebnis“ -, aber es ist tatsächlich eine falsche.
Stellen Sie sich nun vor, Sie führen 100 statistische Tests gleichzeitig durch. Bei einem Alpha-Level von 0,05 besteht nur eine 5% ige Wahrscheinlichkeit, mit einem einzelnen Test eine falsche Entdeckung zu machen. Da Sie jedoch so viele Tests durchführen, würden Sie erwarten, dass etwa 5 der 100 zu falschen Entdeckungen führen.
In der modernen Welt können falsche Entdeckungen ein häufiges Problem sein, da die Technologie es Forschern ermöglicht hat, Hunderte oder sogar Tausende statistischer Tests gleichzeitig durchzuführen. Zum Beispiel können medizinische Forscher statistische Tests an Zehntausenden von Genen gleichzeitig durchführen. Selbst bei einer Rate falscher Entdeckungen von nur 5% bedeutet dies, dass Hunderte von Tests zu falschen Entdeckungen führen können.
Eine Möglichkeit, die Rate falscher Entdeckungen zu kontrollieren, besteht darin, das sogenannte Benjamini-Hochberg-Verfahren zu verwenden.
Das Benjamini-Hochberg-Verfahren funktioniert wie folgt:
Schritt 1: Führen Sie alle statistischen Tests durch und ermitteln Sie den p-Wert für jeden Test.
Schritt 2: Ordnen Sie die p-Werte in der Reihenfolge vom kleinsten zum größten an und weisen Sie jedem einen Rang zu – der kleinste p-Wert hat einen Rang von 1, der nächstkleinere einen Rang von 2 usw.
Schritt 3: Berechnen Sie den kritischen Benjamini-Hochberg-Wert für jeden p-Wert mit der Formel
(i / m) * Q.
wobei:
Schritt 4: Finden Sie den größten p-Wert, der kleiner als der kritische Wert ist. Bestimmen Sie jeden p-Wert, der kleiner als dieser p-Wert ist, als signifikant.
Das folgende Beispiel zeigt, wie dieses Verfahren mit konkreten Werten durchgeführt wird.
Angenommen, Forscher möchten herausfinden, ob 20 verschiedene Variablen mit Herzerkrankungen zusammenhängen oder nicht. Sie führen 20 individuelle statistische Tests gleichzeitig durch und erhalten für jeden Test einen p-Wert. Die folgende Tabelle zeigt die p-Werte für jeden Test in der Reihenfolge vom kleinsten zum größten.
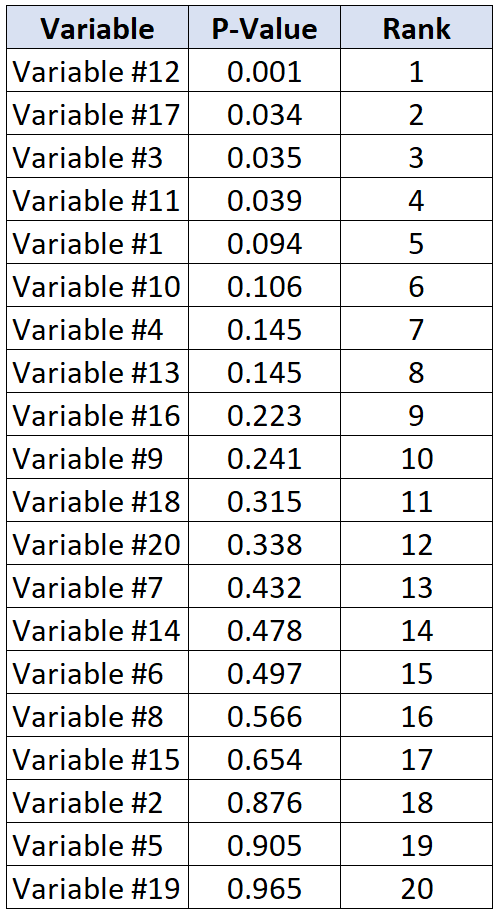
Angenommen, die Forscher sind bereit, eine 20% ige Rate falscher Entdeckungen zu akzeptieren. Um den kritischen Benjamini-Hochberg-Wert für jeden p-Wert zu berechnen, können wir die folgende Formel verwenden: (i / 20) * 0,2 wobei i = Rang des p-Werts.
Die folgende Tabelle zeigt den kritischen Benjamini-Hochberg-Wert für jeden einzelnen p-Wert:
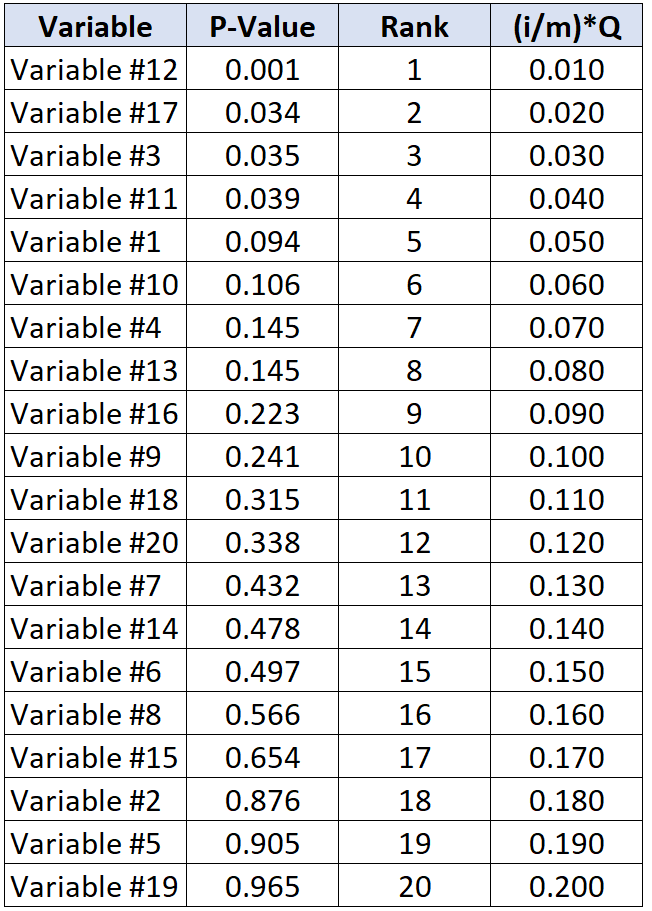
Der Test mit dem größten p-Wert, der unter seinem kritischen Benjamini-Hochberg-Wert liegt, ist die Variable Nr. 11 mit einem p-Wert von 0,039 und einem kritischen BH-Wert von 0,040. Somit werden dieser Test und alle Tests mit einem kleineren p-Wert als signifikant angesehen.
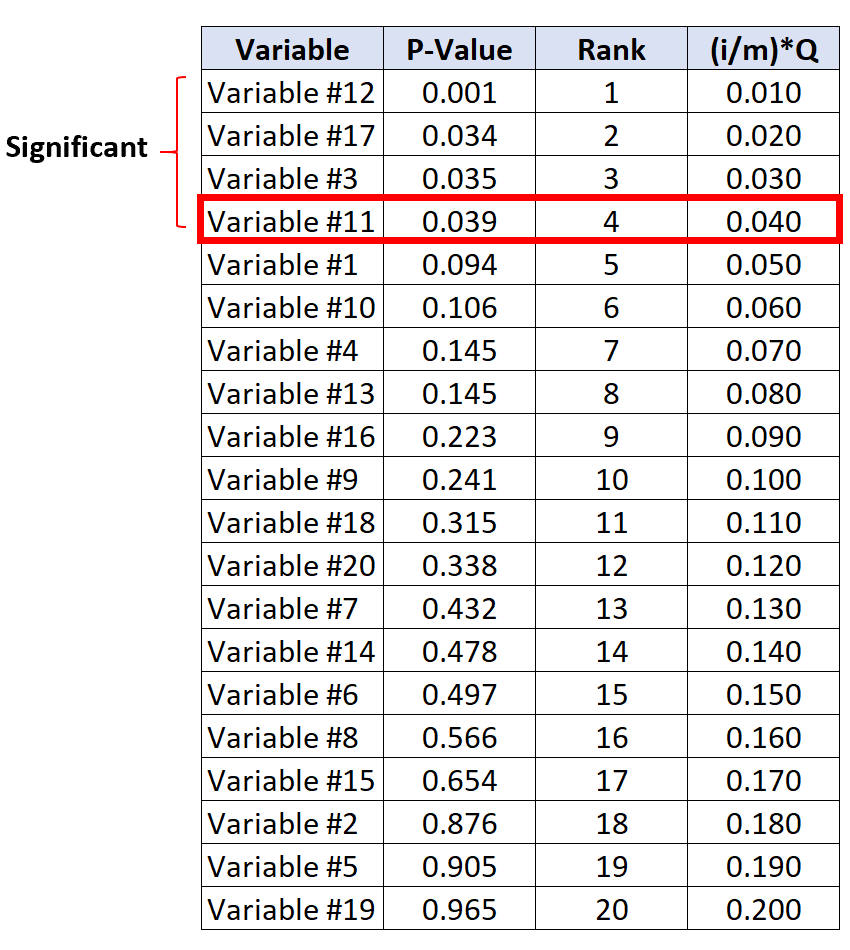
Beachten Sie, dass Variable # 17 und Variable # 3 zwar keine p-Werte hatten, die kleiner als ihre kritischen BH-Werte waren, sie jedoch als signifikant angesehen werden, da sie kleinere p-Werte als Variable # 11 haben.
Einer der wichtigsten Schritte im Benjamini-Hochberg-Verfahren ist die Wahl einer falschen Entdeckungsrate. Sie sollten Ihre Rate falscher Entdeckungen auswählen, bevor Sie tatsächlich Daten erfassen oder statistische Tests durchführen.
In der Regel führen Sie während der Erkundungsphase Ihrer Analyse eine große Anzahl statistischer Tests durch. Anschließend werden weitere Tests durchgeführt, um Ihre Ergebnisse weiter zu untersuchen. Wenn die Folgetests kostengünstig sind, können Sie eine höhere Rate falscher Entdeckungen festlegen, da Sie diese falschen Entdeckungen wahrscheinlich auch bei zukünftigen Tests aufdecken, wenn Sie einige falsche Entdeckungen haben.
Wenn die Kosten für das Fehlen einer wichtigen Entdeckung hoch sind, können Sie die Rate falscher Entdeckungen höher einstellen, damit Sie nichts Wichtiges verpassen.
Abhängig von den Kosten Ihrer Forschung und der Wichtigkeit, keine wichtigen Entdeckungen zu verpassen, variiert die Rate falscher Entdeckungen von einer Situation zur nächsten.
Das Latin Hypercube Stichprobenverfahren ist eine Methode, die zur Stichprobenziehung von Zufallszahlen verwendet werden kann, bei der die Stichproben gleichmäßig über einen Stichprobenraum verteilt sind.
Es wird häufig verwendet, um …
Zwei der wichtigsten Arten von Variablen, die in der Statistik zu verstehen sind, sind erklärende Variablen und Antwortvariablen.
Erklärende Variable: Diese Variable wird manchmal als unabhängige Variable oder Prädiktorvariable bezeichnet …