
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
- K: Die Anzahl der Modellparameter …
Die lineare Regression ist eine nützliche statistische Methode, mit der wir die Beziehung zwischen zwei Variablen, x und y, verstehen können. Bevor wir jedoch eine lineare Regression durchführen, müssen wir zunächst sicherstellen, dass vier Annahmen erfüllt sind:
1. Lineare Beziehung: Es besteht eine lineare Beziehung zwischen der unabhängigen Variablen x und der abhängigen Variablen y.
2. Unabhängigkeit: Die Residuen sind unabhängig. Insbesondere gibt es keine Korrelation zwischen aufeinanderfolgenden Residuen in Zeitreihendaten.
3. Homoskedastizität: Die Residuen weisen auf jeder Ebene von x eine konstante Varianz auf.
4. Normalverteilung: Die Residuen des Modells sind normalverteilt.
Wenn eine oder mehrere dieser Annahmen verletzt werden, können die Ergebnisse unserer linearen Regression unzuverlässig oder sogar irreführend sein.
In diesem Beitrag erklären wir für jede Annahme, wie festgestellt wird, ob die Annahme erfüllt ist, und was zu tun ist, wenn die Annahme verletzt wird.
Die erste Annahme der linearen Regression ist, dass es eine lineare Beziehung zwischen der unabhängigen Variablen x und der unabhängigen Variablen y gibt.
Der einfachste Weg, um festzustellen, ob diese Annahme erfüllt ist, besteht darin, ein Streudiagramm von x gegen y zu erstellen. Auf diese Weise können Sie visuell feststellen, ob zwischen den beiden Variablen eine lineare Beziehung besteht. Wenn es so aussieht, als könnten die Punkte im Diagramm entlang einer geraden Linie fallen, besteht eine Art lineare Beziehung zwischen den beiden Variablen, und diese Annahme ist erfüllt.
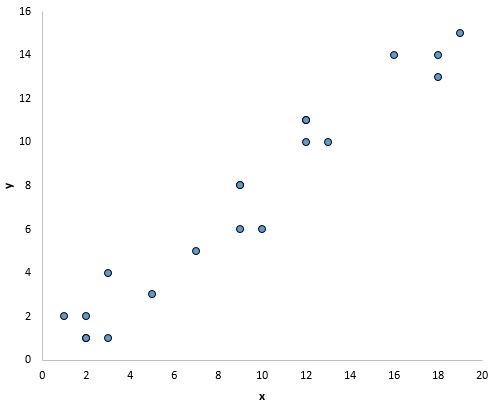
Zum Beispiel sehen die Punkte in der Darstellung unten so aus, als würden sie ungefähr auf eine gerade Linie fallen, was darauf hinweist, dass es eine lineare Beziehung zwischen x und y gibt:
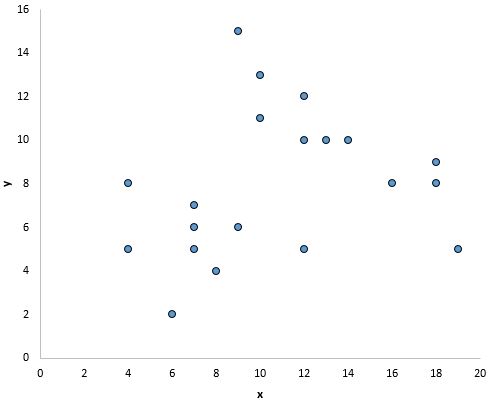
In der folgenden Darstellung scheint es jedoch keine lineare Beziehung zwischen x und y zu geben:
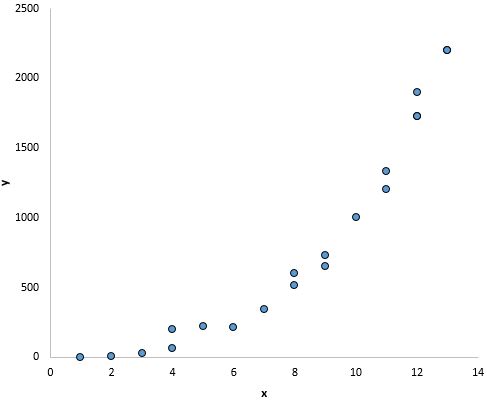
Und in dieser Darstellung scheint es eine klare Beziehung zwischen x und y zu geben, aber keine lineare Beziehung :
Wenn Sie ein Streudiagramm mit Werten für x und y erstellen und feststellen, dass zwischen den beiden Variablen keine lineare Beziehung besteht, haben Sie mehrere Möglichkeiten:
1. Wenden Sie eine nichtlineare Transformation auf die unabhängige und / oder abhängige Variable an. Häufige Beispiele sind das Protokoll, die Quadratwurzel oder der Kehrwert der unabhängigen und / oder abhängigen Variablen.
2. Fügen Sie dem Modell eine weitere unabhängige Variable hinzu. Wenn beispielsweise die Darstellung von x gegen y eine parabolische Form hat, kann es sinnvoll sein, X 2 als zusätzliche unabhängige Variable im Modell hinzuzufügen.
Die nächste Annahme der linearen Regression ist, dass die Residuen unabhängig sind. Dies ist vor allem bei der Arbeit mit Zeitreihendaten relevant. Idealerweise möchten wir nicht, dass es ein Muster zwischen aufeinanderfolgenden Residuen gibt. Beispielsweise sollten Residuen im Laufe der Zeit nicht stetig größer werden.
Der einfachste Weg, um zu testen, ob diese Annahme erfüllt ist, besteht darin, ein Residuum-Zeitreihendiagramm zu betrachten, das ein Residuum der Residuen gegen die Zeit ist. Idealerweise sollten die meisten verbleibenden Autokorrelationen innerhalb der 95%-Konfidenzbänder um Null liegen, die sich etwa +/- 2 über der Quadratwurzel von n befinden, wobei n die Stichprobengröße ist. Mit dem Durbin-Watson-Test können Sie auch formal testen, ob diese Annahme erfüllt ist.
Abhängig von der Art und Weise, wie diese Annahme verletzt wird, haben Sie einige Möglichkeiten:
Die nächste Annahme der linearen Regression ist, dass die Residuen auf jeder Ebene von x eine konstante Varianz aufweisen. Dies ist als Homoskedastizität bekannt. Wenn dies nicht der Fall ist, sollen die Residuen unter Heteroskedastizität leiden.
Wenn in einer Regressionsanalyse Heteroskedastizität vorliegt, sind die Ergebnisse der Analyse schwer zu vertrauen. Insbesondere erhöht die Heteroskedastizität die Varianz der Regressionskoeffizientenschätzungen, aber das Regressionsmodell greift dies nicht auf. Dies macht es für ein Regressionsmodell viel wahrscheinlicher, zu erklären, dass ein Begriff im Modell statistisch signifikant ist, obwohl dies tatsächlich nicht der Fall ist.
Der einfachste Weg, Heteroskedastizität zu erkennen, besteht darin, einen angepassten Wert gegenüber dem Residuenplot zu erstellen.
Sobald Sie eine Regressionslinie an einen Datensatz angepasst haben, können Sie ein Streudiagramm erstellen, in dem die angepassten Werte des Modells im Vergleich zu den Residuen dieser angepassten Werte angezeigt werden. Das Streudiagramm unten zeigt ein typisches angepasstes Wert-Residuen-Diagramm, in dem Heteroskedastizität vorliegt.
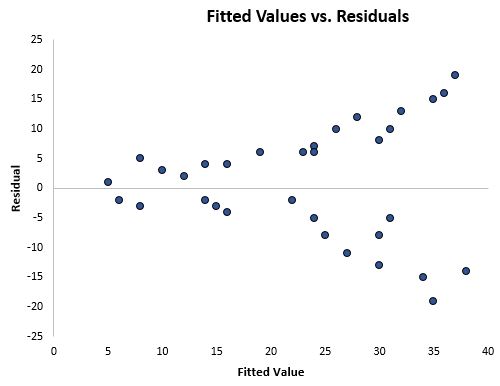
Beachten Sie, wie sich die Residuen viel weiter ausbreiten, wenn die angepassten Werte größer werden. Diese „Kegel“-Form ist ein klassisches Zeichen für Heteroskedastizität:
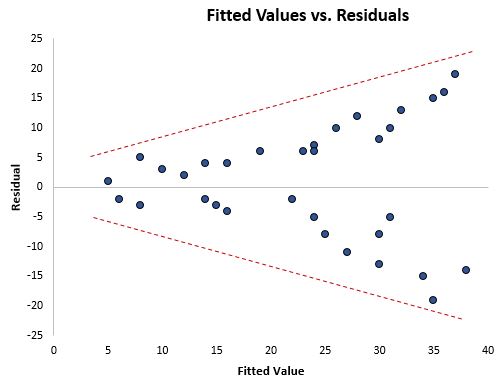
Es gibt drei gängige Methoden, um die Heteroskedastizität zu beheben:
1. Transformieren Sie die abhängige Variable. Eine übliche Transformation besteht darin, einfach das Protokoll der abhängigen Variablen zu erstellen. Wenn wir beispielsweise die Bevölkerungsgröße (unabhängige Variable) verwenden, um die Anzahl der Blumenläden in einer Stadt vorherzusagen (abhängige Variable), können wir stattdessen versuchen, die Bevölkerungsgröße zu verwenden, um das Protokoll der Anzahl der Blumenläden in einer Stadt vorherzusagen. Die Verwendung des Protokolls der abhängigen Variablen anstelle der ursprünglichen abhängigen Variablen führt häufig dazu, dass die Heteroskedastizität verschwindet.
2. Definieren Sie die abhängige Variable neu. Eine übliche Methode zur Neudefinition der abhängigen Variablen ist die Verwendung einer Rate anstelle des Rohwerts. Anstatt beispielsweise die Bevölkerungsgröße zur Vorhersage der Anzahl der Blumenläden in einer Stadt zu verwenden, können wir stattdessen die Bevölkerungsgröße zur Vorhersage der Anzahl der Blumenläden pro Kopf verwenden. In den meisten Fällen verringert dies die Variabilität, die natürlich bei größeren Populationen auftritt, da wir eher die Anzahl der Blumenläden pro Person als die schiere Anzahl der Blumenläden messen.
3. Verwenden Sie die gewichtete Regression. Eine andere Möglichkeit, die Heteroskedastizität zu beheben, ist die gewichtete Regression. Diese Art der Regression weist jedem Datenpunkt eine Gewichtung basierend auf der Varianz seines angepassten Werts zu. Dies gibt Datenpunkten mit höheren Varianzen im Wesentlichen kleine Gewichte, wodurch ihre quadratischen Residuen verkleinert werden. Wenn die richtigen Gewichte verwendet werden, kann dies das Problem der Heteroskedastizität beseitigen.
Die nächste Annahme der linearen Regression ist, dass die Residuen normal verteilt sind.
Es gibt zwei gängige Methoden, um zu überprüfen, ob diese Annahme erfüllt ist:
1. Überprüfen Sie die Annahme visuell anhand von QQ-Plots.
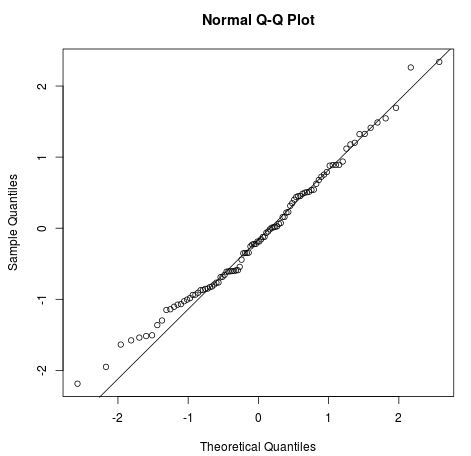
Ein QQ-Plot, kurz für Quantil-Quantil-Plot, ist ein Plottyp, mit dem wir bestimmen können, ob die Residuen eines Modells einer Normalverteilung folgen oder nicht. Wenn die Punkte auf dem Plot ungefähr eine gerade diagonale Linie bilden, ist die Annahme einer Normalverteilung erfüllt.
Das folgende QQ-Diagramm zeigt ein Beispiel für Residuen, die ungefähr einer Normalverteilung folgen:
Das folgende QQ-Diagramm zeigt jedoch ein Beispiel dafür, wann die Residuen deutlich von einer geraden diagonalen Linie abweichen, was darauf hinweist, dass sie nicht der Normalverteilung folgen:
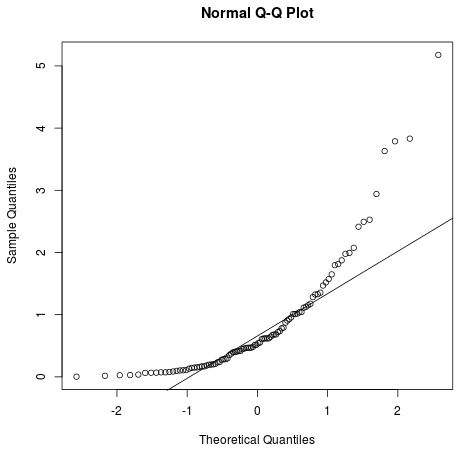
2. Sie können die Annahme einer Normalverteilung auch mit formalen statistischen Tests wie Shapiro-Wilk, Kolmogorov-Smironov, Jarque-Barre oder D’Agostino-Pearson überprüfen. Beachten Sie jedoch, dass diese Tests für große Stichprobengrößen empfindlich sind. Das heißt, sie kommen häufig zu dem Schluss, dass die Residuen bei großen Stichproben nicht normal sind. Aus diesem Grund ist es oft einfacher, nur grafische Methoden wie ein QQ-Diagramm zu verwenden, um diese Annahme zu überprüfen.
Wenn die Annahme der Normalverteilung verletzt wird, haben Sie einige Möglichkeiten:
Weiterführende Literatur:
Das Akaike-Informationskriterium (AIC) ist eine Metrik, die verwendet wird, um die Anpassung verschiedener Regressionsmodelle zu vergleichen.
Es wird berechnet als:
AIC = 2K – 2ln (L)
wo:
Die logistische Regression ist eine statistische Methode, die wir verwenden, um ein Regressionsmodell anzupassen, wenn die Antwortvariable binär ist.
Um zu beurteilen, wie gut ein logistisches Regressionsmodell zu einem Datensatz …